1 日語的來源
日語的系屬未能確定。有學者認為,日語可能是由南島語和朝鮮語融合而成。說南島語的一些民族,可能早在遠古時代就渡海至日本諸島定居 ;公元前約三世紀中葉,當朝鮮半島南端的部分住民東徙至日本島,朝鮮語就慢慢與南島語融合,從而產生了原始日本語。所以在語音上,日本語跟南島語如夏威夷語和印尼語有許多相似之處,例如音節結構簡單,元音為數不多,而在語法上則跟朝鮮語有不少相近的地方,例如動詞常置於句子未端,動詞的不同時態是靠詞幹後面的不同詞綴來表示,等等。
2 日文是怎樣產生的
由最初嘗試借用漢字書寫日語到現代日文初步形成,需時起碼數百年。學者一般認為,漢字自中國經朝鮮傳到日本,但何時傳入,則眾説紛紜,有人説是公元二世紀(中國東漢)或更早。
漢字是專為書寫漢語而產生的,借用來寫外語不一定很適合。日語和漢語是兩種很不同的語言,所以借用漢字書寫日語,起初無可避免會遇到很大的困難,但經過數百年的反覆試驗,終於產生了日文的雛形。
怎樣用漢字寫日語
在日文雛形產生之前,怎樣用漢字寫日語,不同的人會有不同的意見,不容易達成共識,尤其是在初期。日本人最初學習古漢文時,會發覺用漢文寫出心中的意思,反而會比用漢字寫日語容易一些。公元五世紀初(中國南北朝初),學習古漢文的日本人日漸增多,這爲日後創造日文提供了最基本的條件。精通漢文的日本人,可以說是創造日文的最理想人選。
眾所周知,漢字有形、音、義。一個漢字代表漢語中的一個詞或語素,而由於語素既有音、亦有義,所以漢字亦有音有義。漢語語素基本上都是單音節,所以一個漢字只有一個單音節的讀音。在漢文中,漢字有時亦會作單音節音符使用,例如〈愛因斯坦〉和〈倫敦〉這些外國人名和地名,便是將漢字作音符用,寫出名字的讀音。
用漢字作音符來寫日本名字
日本人學習古漢文時,很可能亦同時學會這種書寫外國名字的方法。從日本一把古鐵劍上的銘文可以見到,有人早在公元五世紀便利用漢字作音符,來書寫日本人的名字。這把古劍於 1968 年出土自日本琦玉縣稻荷山古墳,估計製成於公元 471 年或一個甲子後的 531 年(中國南北朝時代)。劍上的銘文是用古漢文寫成(見下表),記有十個日本名字(以粗體字顯示),包括鑄劍者八代人的名字。這十個名字都是把漢字作音符使用,每個漢字基本上代表名字中的一個音節讀音,例如意富比垝這個名字代表オホヒコ這四個音節(今日讀成 ohohiko),但也有例外,例如多加利足尼這個名字中的足字要讀成スク suku 兩個音節。而且,名字的讀法要按日本語的習慣在有需要時加上虚詞,換句話說,名字中的虚詞毋須寫出來。這些名字是日本歷史上最早把漢字用作音符的最著名例子。

日本名字是日語的一部分。當日本人跟隨漢文書寫外國人名和地名的習慣,用漢字寫出日本名字的讀音時,他們就不經意的為日文的創造走出了第一步。日本名字既然可以用漢字把其讀音寫出來,日語其他的詞彙,可否用同樣方法寫出來呢?
怎樣用古漢文書寫口述的日本歷史
日本最古老的歷史書是《古事記》,編撰者為安萬侶。公元 711 年,日皇命安萬侶撰錄稗田阿禮所口誦之日本歷史故事。稗田阿禮負責口誦故事,所用的語言當然是日本口語,安萬侶負責撰錄故事,所用的文字卻基本上是古漢文。換句話説,安萬侶基本上要把口誦日語的意思翻譯成漢文。從《古事記》正文開頭的部分可以見到,安萬侶譯寫日語時基本上只有兩種做法:一是把日語的意思翻譯成漢文,一是把日語的讀音用漢字寫出來。這兩種做法分別涉及日語詞彙的意譯和音譯。由於用漢字意譯或音譯日語詞彙是創造日文兩種最基本的方法,所以安萬侶用漢字意譯或音譯日本口語,實際上已經為日文的創造邁出了重要的一步。《古事記》譯寫自日本口語,譯寫成的文字雖然帶有濃厚日語色彩,但基本上仍可算是漢文。《古事記》成書於公元 712 年,可見在八世紀初(中國唐代),日本的正式記事文字基本上是漢文。
在《古事記》序文的結尾中,安萬侶講述了他用漢文譯寫日語所遇到的困難,以及他的解決方法。他這樣寫(原文並沒有標點符號):
「上古之時,言意並朴,敷文構句,於字卽難。已因訓述者,詞不逮心;全以音連者,事趣更長。是以今,或一句之中,交用音訓;或一事之內,全以訓錄。卽,辭理叵見,以注明;意況易解,更非注。」
上文的大意是:上古之時,語詞簡樸,用漢字遣詞造句來表達其意思不免會有困難。如果都用漢字表意,日語原本的意思就難以完全表達。如果都用漢字表音,文句就會變得冗長。所以現在於一句之中,或表意表音並用,或全部表意。詞意若難以理解,則用注釋說明;若詞意易明,就毋須注明。
下面列出《古事記》正文的開頭部分(原文沒有標點符號),用以説明安萬侶用漢文譯寫日語所遇到之困難,以及其解決方法 (因為技術原因,較細小的字型不能在此顯示,我們只好用斜體藍字來表示細字):
「天地初發之時,於高天原成神,名天之御中主神訓高下天,云阿麻。下效此、次高御產巢日神、次神產巢日神。此三柱神者,並獨神,成坐而隱身也。次國稚如浮脂而久羅下那州多陀用幣流之時流字以上十字以音,如葦牙,因萌騰之物而成神,名宇摩志阿斯訶備比古遲神此神名以音、次天之常立神訓常云登許,訓立云多知。此二柱神亦獨神,成坐而隱身也。上件五柱神者,別天神。」
安萬侶譯寫日語時,遣詞造句雖然說是以漢文為本,但在用字、詞組以至句子結構方面,難免會受到原本的日語所影響。上文提過,《古事記》正文並沒有標點符號。跟據稗田阿禮口誦之日語,安萬侶把第一句寫成 : 〈天地初發之時於高天原成神名天之御中主神〉;而跟據安萬侶的譯文,稗田阿禮在遣詞造句方面有可能說出類似表 2 中羅馬字所示的話 : Ame tsuchi …。[1] 如果真的這樣,安萬侶用漢字會怎樣譯寫這句話呢?

上表中的漢字,把日語詞逐個意譯出來,並按日語語序排列。從這些漢字的排列次序,可以看到這句日語的語序跟漢語很接近,只有{於}這個虛詞,在兩種語言中的語序明顯不同,漢語說{於高天原},日語則說{高天之原於},安萬侶按漢文習慣寫成〈於高天原〉。但請注意,{高天原}的語序,在兩種語言中卻基本上是一樣的。〈高天原〉有可能來自日語詞組 たかまのはら takama no hara 的意譯。日語詞 たか taka 解作‘高’, あま ama 解作‘天’,在口語中這兩個詞往往合併為 たかま takama,の no 是語法虚詞,解作‘的’,而はら hara 解作‘平原’;整個詞組的意思是‘高天之上的平原’,指神的居所。〈高天原〉基本上是用一個漢字對應一個實詞的方法寫出來的:〈高〉對應 taka,〈天〉對應 ama,〈原〉對應 hara。
在日語中,‘天’的意思有幾種講法,所以安萬侶在正文中要用細字注明〈高天原〉中〈天〉的讀法:訓高下天,云阿麻。下效此。即是說,〈高〉字下面的〈天〉要訓讀成 /阿麻/,以後都是這樣做。所謂訓讀,是指用日語把字的意思讀出來。假如有人把日語詞組{takama no hara ni}寫成〈高天之原於〉,那就表示他是按日語語序直接寫日語,而不是把日語翻譯成漢文。換言之,〈高天之原於〉可以看作是日文,而不是漢文。
日語{takama no hara ni nareru kami no na wa …}的意思是‘成形於高天原的神的名字是……’,古漢文可寫成〈於高天原成神者之名為……〉,安萬侶則寫成〈於高天原成神名……〉。安萬侶把句子後截寫成〈成神名〉,可能是受了日語{nareru kami no na wa …}的影響,只用〈成〉、〈神〉、〈名〉這三個漢字,分別寫出{nareru}、{kami}、{na}三個實詞,而虛詞{no}和{wa}則不寫。{no}可以用〈之〉字寫出來,如〈天之御中主神〉中的〈之〉字,安萬侶可以寫成〈於高天原成神之名……〉,但{no}在漢文中很多時毋須譯出來。至於{wa},是日語常用的虛詞,在漢語中卻不容易找到一個相對應的虛詞。{wa}這裏用來提示這句話的主題是名字。日語通常會在{wa}後面稍作停頓,以突顯主題,所以日本人會按日語習慣,在〈成神名〉之後插入逗號,把句子後截標點成〈於高天原成神名、天之御中主神〉。漢人看到這一句,會覺得逗號應該置於〈名〉之前,如果再把句子寫成〈於高天原成神者,名天之御中主神〉,意思就會更加清楚了。
用漢字把日語實詞逐一寫出來的另一個例子是〈別天神〉。〈別天神〉有可能是意譯自日語詞組 ことあまつかみ koto ama tsu kami 。日語詞 こと koto 解作‘特殊’或‘與別不同’,あま ama 解作‘天’,つ tsu 是語法虚詞,解作‘的’,而 かみ kami 解作‘神’;整個詞的意思是‘與別不同的天神’。〈別天神〉基本上也是用一個漢字對應一個實詞的方法寫出來的。
用漢字寫出日語詞彙的意思
《古事記》正文開頭所提及的五個天神名當中,只有一個是用漢字寫其音,其餘四個都是用漢字寫其意。這四個用漢字寫其意的神名為:天之御中主神、高御產巢日神、神產巢日神、天之常立神。以天之常立神為例,其寫法相信是來自日語詞組 あめのとこたちのかみ ame no toko tachi no kami 的意譯。日語詞 あめ ame 解作‘天’,のno是語法虚詞,解作‘的’或較文言的‘之’,とこ toko 解作‘恆常’,たち tachi 解作‘站立’,而 かみ kami 解作‘神’;整個詞的意思是‘天上的恆常站立的神’。〈天之常立神〉是用一個漢字對應一個實詞或虚詞的方法寫出來的。安萬侶把名字寫成〈天之常立神〉時,可能因為〈常立〉有多種解讀,所以要在該神名下面用細字 訓常云登許,訓立云多知 來說明〈常立〉的日語讀音。即是說,〈常〉和〈立〉要分別訓讀成 /登許/ 和 /多知/。有了注釋的幫助,讀者就會很容易知道〈常立〉的意思。
用漢字寫出日語詞彙的音
上一段説過,只有一個神名是用漢字寫其音,即是説,書寫該神名所用的漢字都是當音符用。安萬侶在寫出這個神名之前,先簡略解釋該神名背後的意義。這段解釋,原文是這樣寫的:〈次國稚如浮脂而久羅下那州多陀用幣流之時流字以上十字以音,如葦牙,因萌騰之物而成神〉,大意是‘國土初開之時,如脂肪般浮動,如水母般漂蕩,神就如蘆葦萌發嫩芽般成形’。在原文中的〈久羅下那州多陀用幣流〉之後,安萬侶用細字流字以上十字以音明確指出,這十個漢字是作音符用。〈久羅下〉、〈那州〉、〈多陀用幣流〉分別把日語詞くらげ kurage、なす nasu、ただよへる tadayoheru 逐個音節寫出來。日語詞 kurage、nasu、tadayoheru 分別解作‘水母’、‘好像’、‘漂蕩’,所以整句解作‘如水母般漂蕩’。
上一段安萬侶的解釋,只有〈久羅下那州多陀用幣流〉這一小段是把原來的日語用漢字作音符寫出來,其他部分都是意譯。安萬侶只選擇把這段話音譯出來,其原因無從猜測,只知道音譯這段日語,對安萬侶來說並不困難。〈久羅下那州多陀用幣流〉這段譯文,可以看作是日文,而不是漢文。安萬侶這樣寫日語是否理想,其他人閱讀時便會發覺。安萬侶是創造日文的先行者之一。
安萬侶作出解釋之後,便將神名寫出來:〈宇摩志阿斯訶備比古遲神〉,接着在名字後面用細字注明:此神名以音。有了這樣簡略的解釋和注釋,日本人就可以按這十個漢字的讀音,猜想出是日本神話中哪一個神,從而能夠用日語把該神名準確地讀出來。〈宇摩志阿斯訶備比古遲神〉,很可能譯自日語 ウマシアシカビヒコヂノカミ umashi ashi kabi hikoji no kami,結尾的〈神〉字意譯自kami,而其餘的漢字則都是用作音符。〈宇摩志〉、〈阿斯〉、〈訶備〉、〈比古遲〉,分別把日語詞 umashi、ashi、kabi、hikoji 逐個音節寫出來。日語詞 umashi、ashi、kabi、hikoji 分別解作‘美好’、‘蘆葦’、‘發芽’、‘俊彥’。這個神的名字,在《日本書紀》這本跟《古事記》性質類似、年代相近的書中,意譯成〈可美葦牙彥舅尊〉。
公元八世紀初,假名仍未產生,日語的讀音還沒有標準的漢字寫法,同一個音,不同的人可能會用不同的漢字來代表。光看漢字,不一定能夠聯繫到其所想代表的日語讀音。沒有神名的解釋,光看當音符用的漢字,相信就要多花一點工夫才能推敲出是哪一個神。
日本名字的讀法
安萬侶在《古事記》序文的結尾中,除了講述用漢文譯寫日語的方法外,還用了一個日本名字做例子,來解釋日本名字的讀法要依隨名字原本的稱謂。原文是:「亦,於姓日下謂玖沙訶,於名帶字謂多羅斯。如此之類,隨本不改。」大意是‘而見到〈日下〉這個姓氏,要讀成 /玖沙訶/;見到〈帶〉這個名字,要讀成 /多羅斯/。這類姓名的讀法,要依隨原本的稱謂而不改’。日本名字的稱謂有音有義,〈日下帶〉這三個漢字,是把名字的意思寫出來,而〈玖沙訶多羅斯〉這六個漢字,則是把名字的讀音寫出來。
《古事記》怎樣記錄日本歌謠
《古事記》一共收錄了百多首日本歌謠,即所謂的「和歌」。這些和歌當然是用日語來唱。如果要把這些和歌寫出來,最簡單直接的方法是把漢字當音符用,將日語歌詞的讀音逐個音節寫出來。安萬侶筆錄稗田阿禮口誦的古代歷史,只用了四個多月便把書寫成,之所以能夠寫得這樣快,原因之一是可以選擇用漢字寫音的方法記錄和歌。如果用漢字意譯的方法,除了需要時間選用最恰當的漢字來代表日語詞彙外,所用的漢字亦很難完全表達日語歌詞所蘊含的感情。
以下是一首著名的和歌,相傳為日本武尊倭建命東征歸途中思鄉之作。現以該和歌原文的寫法,來顯示安萬侶是怎樣記錄和歌的。在下面的表格中,第一行是歌詞的原文,所用之漢字全都是作音符用,把歌詞讀音逐個音節寫出來;第二行是與漢字音符相對應的近代平假名;第三行是用多數讀者都看得懂的羅馬字,來顯示歌詞的讀音;[2] 第四行是把第二行一些實義詞用漢字把其意思寫出來,混合使用漢字和假名來寫日語,會比純用假名更容易閱讀;第五行是歌詞的大意。
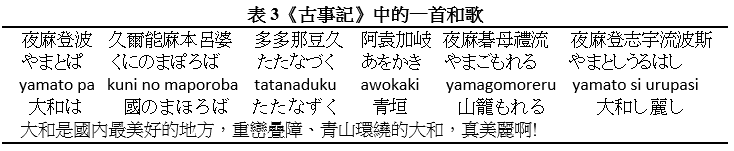
安萬侶用寫音的方法記錄和歌,有利亦有弊。好處是容易寫,亦頗能準確地顯示出日語的讀音。弊處是不容易閱讀,原因主要有兩種。第一是分詞的問題,原文相信是把歌詞一連串地寫出來,中間並沒有標點符號或間隔空間。相信讀者需要把句子閱讀多遍才能推敲出句子中的各個用辭。第二是日語的音節,那時還沒有一個固定的漢字來代表。換句話說,一個日語詞的讀音未必有一個固定的寫法。讀者見到一組漢字音符,未必能夠很快認到是哪一個日語詞。
用漢字記錄日本歌謠的《萬葉集》
談到記錄和歌的方法,不能不提《萬葉集》。《萬葉集》是最古老的日本詩歌集,收錄了由四世紀至八世紀年間的四千五百多首長短不一的和歌。編纂者有多人,最重要的編者是大伴家持。編纂的年代由七世紀後半葉至八世紀後半葉(中國唐代),歷時約一百年。要用漢字記錄四千多首和歌,必然涉及各種以漢字書寫日語的方法,日本人從記錄和歌中積累了許多書寫日語的寶貴經驗,會慢慢摸索出寫日語的最佳辦法,這種種經驗對現代日文的創造有很大的幫助。
用漢字寫出歌詞的意思
現以幾首有代表性的和歌,來顯示以漢字書寫日語的主要方法。首先介紹《萬葉集》中字數最少、編號 2453 的一首和歌,歌詞原文見下表中第一行。這首和歌嘗試用十個漢字將歌詞的意思寫出來,文字十分簡潔,讀者即使不懂日文,大概也能從這十個漢字隱約知道歌詞的大意。

上表中第二、三行,以平假名及羅馬字顯示第一行中十個漢字所代表的日語。之所以能夠重構出如第二、三行所顯示的日語,是因為日本學者首先假設這首和歌是依循 5/7/5/7/7 共 31 個音節的一般格式,再根據十個漢字的意思,絞盡腦汁地把歌詞中的實詞以及虛詞(下面劃綫)擬構出來。歌詞分五段,現逐一介紹如下:(一)paru 是春天的意思,yanagwi 指楊柳樹,paruyanagwi 共 5 個音節;(二)kadura 指葛這種植物,kwi 是樹的意思,yama 指山,kadurakwiyama 是指奈良縣的葛城山, ni 是表示地點的助詞,kadurakwiyama ni 共 7 個音節;(三)tatu 解作‘升起’,kumo 指雲,no 是語氣助詞,tatu kumo no 共 5 個音節;(四)tatite 是起立的意思,wite 則是停留的意思,mo…mo 是並列助詞,解作‘又…..又’,tatite mo wite mo 解作‘無論坐或立’,共 7 個音節;(五)imo 是指情人,omopu 是思念的意思,wo 是助詞,指出 imo 是賓詞,si so 是語氣助詞,imo wo si so omopu 共 7 個音節。
如果這首和歌沒有 31 個音節的格式規範,相信不同的人會重構出不同的日語,而這些日語不一定跟上表所示的日語相同。
用漢字寫出歌詞的讀音
表 4 中的和歌用漢字表義,以下介紹的一首和歌則用漢字表音。這首和歌在《萬葉集》中的編號為 3373,歌詞的原文見下面表 5 中的第一行。原文沒有間斷,但為了方便閱讀起見,按和歌 31 個音節的格式規範,把原文分為五段寫出來。第一行所用之漢字都是作音符用,把歌詞讀音逐個音節寫出來;第二行是與漢字音符相對應的平假名;第三行是用羅馬字顯示歌詞的音;第四行是混合使用漢字和假名來寫日語,方便閱讀;第五行是用中文把歌詞的意思逐段譯出來;第六行是整首和歌的中文意譯。

這首和歌的原文,相信是把歌詞一連串地寫出來,中間並沒有標點符號或間隔空間把詞組分開。原文本來不容易閱讀,但因為有了和歌 31 個音節的格式規範,歌詞原文可以按 5/7/5/7/7 的音節格式分為五段,閱讀會變得較為容易。原文分了五小段,日本人藉母語之助,只要把每段的漢字音符讀出來,相信很快就會明白歌詞的意思,以及容易把句子分成一個一個詞。上文說過,用漢字音符寫日語,在閱讀方面還有一些不便之處,原因是當時還沒有一個固定的漢字代表一個日語音節。換句話說,一個日語詞的讀音未必有一個固定的寫法。讀者見到一組漢字音符,未必能夠立刻認到是哪一個日語詞。
日本人要注出日語的音節,可供選擇的漢字有多個。在日文初創時期,同一個日語音節可以用不同的漢字寫出來。即使同一個作者,亦可能會用不同的漢字寫同一個日語音節。以表 5 中的和歌為例,ko 這個音節就有兩種不同的寫法:〈許〉和〈己〉。日本人學漢文時,會學習漢字的音和義。〈許〉和〈己〉字的漢語讀音最接近日語的 ko,所以就借〈許〉和〈己〉字來代表 ko 音。在《萬葉集》中,寫日語 ko 的漢字音符,除了〈許〉和〈己〉字之外,還有〈巨、去、居、忌、虚、興、木〉等字。
這首和歌中的〈児〉字,現代日語讀 ko,古音大概是 kwo,在這裏可否看作是音符則有疑問。〈児〉字的日語漢音是 ji 或 ni,在漢文中解作‘男兒’或‘女兒’,在這首歌裏則解作‘女兒’或‘姑娘’,按日語可訓讀成 kwo(古音)或 ko(今音)。所以歌中的〈児〉字應該不是作音符用,而是意譯自日語的 kwo(或 ko)。由於〈児〉是常用字,而且經常會訓讀,而訓讀的音又恰好是單音節,所以當要寫日語的 kwo(或 ko)時,可能會不自覺地把〈児〉字作音符用。 kwo(或 ko)這個詞是整首歌的焦點,如果用〈古〉或〈故〉這些音符寫,就不能把 kwo這個詞突顯出來;寫成〈児〉字,則恰好音義兼顧,亦收突顯之效。
用漢字寫出歌詞的意思或讀音
表 4 和表 5 中的和歌分別用漢字表示日語詞的義和音,以下介紹的一首和歌則用部分漢字表示日語詞的義,部分漢字表示日語詞的音。這首和歌在《萬葉集》中的編號為 690,歌詞的原文見下面表 6 中的第一行。原文沒有間斷,但這裏按和歌 31 個音節的格式,分為五段。第一行所用之漢字,部分表音,部分表義;第二行是用近代的平假名把歌詞寫出來;第三行是用羅馬字顯示歌詞的音;第四行是混合使用漢字和假名來寫日語,方便閱讀;第五行是用中文把歌詞的意思譯出來。
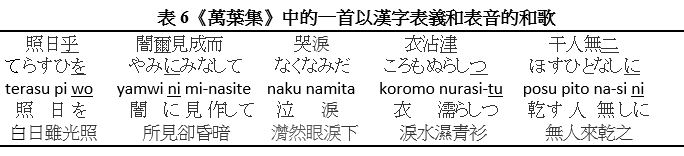
上表把原文分為五段,並在表音字下面劃綫,以便閱讀和重構句子。但原文中所有漢字都沒有分隔開,表音字下面亦沒有劃綫,表義字和表音字混在一起,哪個字是表義,哪個字是表音,單從外形看不容易分辨開來。讀者要小心閱讀,才能弄清楚字與歌詞的關係,重構日語歌詞。
從表 4 至表 6 中的三首和歌可以見到,書寫日語可以有三種方法:(一)把和歌中的日語實詞用漢字寫其義,助詞則不寫;(二)把和歌中的日語詞,包括助詞在內,逐一用漢字寫其音;(三)把和歌中的日語實詞用漢字寫其義,助詞則用漢字寫其音。這三種方法各有利弊,現扼要分述如下:
用漢字寫日語詞義的利弊
第一種方法是用最適當的漢字把日語實詞的意義寫出來,助詞則略過不寫。這種方法的好處是詞與詞之間的界限分得很清楚,一個漢字就代表一個詞,但弊處卻有幾個。第一,助詞略過不寫,讀者重構歌詞時,可能會遇到困難。第二,只用一個漢字,不足以表示日語動詞的各種語法意義。第三,在寫法未有共識之前,一個日語詞可以有多個近義的漢字來表示其意思。讀者見到一個表義的漢字,可能會想起其他的日語近義詞,未必可以肯定所指的日語詞。
先說弊處一。日語中的助詞略過不寫,讀者可能會覺得不方便。助詞如果不容易找到適合的漢字寫其義,用漢字寫其音則容易得多。所以日語助詞的寫法會趨向寫音。
弊處二涉及用漢字書寫日語動詞的問題。日語動詞需要表示時態、主動或被動語態等語法意義,其讀音會隨着這些語法意義而產生變化。例如解作‘食’ 的日語動詞 taberu,過去式讀 tabeta,被動語態讀 taberaremashita,所以只用一個〈食〉字,不足以表示由 taberu 衍生出來的各個動詞。在現代日文中,以 tabe 開頭的各個動詞會用〈食〉加平假名寫出來:〈食〉字表示這些動詞的基本義‘食’,詞幹 tabe 寫成〈食べ〉,而〈食べ〉後面之平假名則表示詞幹 tabe 後面的讀音變化。例如,過去式動詞 tabeta 會寫成〈食べた〉,〈食〉表示基本義;〈べ〉這平假名讀 /be/,用來提示〈食〉在這裏應該讀 /tabe/;〈た〉這平假名讀 /ta/,表示過去式的讀音 /ta/。詞幹 tabe 之所以寫成〈食べ〉,是因為〈食〉字在日文中有幾種讀法。〈食〉除了可以表示 taberu 之外,還可以表示另一個和語動詞 kuu(亦解作‘食’,寫成〈食う〉或〈くう〉)和漢語借詞 shoku(漢字〈食〉的音讀,寫成〈食〉或〈しょく〉)。
弊處三則涉及日語詞與漢字的匹配問題,現以表 4 中解作‘情人’的日語詞 imo 為例來說明。在寫法未有共識之前,作者要找出最適合的漢字來寫出 imo 的意思。他可能會想到〈娘〉[3]、〈女〉、〈妹〉等字。讀者見到這些字,可能會聯想起 musume、onna、me、imo、imouto 這些日語近義詞彙。這些日語詞彙應該用哪些漢字來寫才最適合,需長時間反覆試驗方能達成共識。在現代日文中,〈娘〉代表日語詞 musume,而這詞在日語中指‘女兒’或‘少女’;〈女〉代表日語詞 onna 或 me,而這兩個詞在日語中都指‘女人’;〈妹〉代表日語詞 imo 或 imouto,imo 指‘情人’,而 imouto 一般指‘妹妹’,亦可指‘堂妹’、‘小姑’、‘小姨’等。
日本漢字借自中國漢字,原本並不是用來書寫日語的,古代日本的正式文字是古漢文,即使到了十九世紀末的明治維新時期,日本的公私文字都仍然是以古漢文為主。在古代日本,用漢字書寫日語的情況並不普遍,記錄和歌屬例外。和歌是日語詩歌,用漢字記錄和歌自然會涉及書寫日語的問題。和歌的記錄可以看作是日文的雛形。當一個漢字跟某日語詞掛勾後,這個漢字的意思就由該日語詞的意思來決定。一個漢字可以代表一個或多個日語詞,而這些詞的各種意思決定了這個字在日文中的不同意思。以上一段所提及的〈妹〉字為例,〈妹〉原本代表漢語詞{妹},可借用來代表日語詞 imouto,imouto 的核心意思跟漢語詞{妹}相同,其外圍意思則有所不同。所以日文〈妹〉字的意思跟中文〈妹〉字亦有些出入。日文的〈妹〉字包含‘小姑’或‘小姨’ 這些外圍意思,但中文的〈妹〉字則沒有這些意思。日文〈妹〉字的意思,由日語詞 imouto 的意思來決定,而不是漢語詞{妹}。
一個日語詞之所以匹配某漢字,是因為該漢字與日語詞基本上同義。所以在某種意義上,一個日文漢字的意思,可以説是源自該漢字在當時中文的意思。可是,如上文所述,一旦日文選定該漢字與某日語詞匹配後,該漢字的意思則交由該日語詞來決定,而不是由原來的中文漢字來決定。日文漢字的意思,包括其外圍義,很難跟中文漢字的意思百分百相同。
一個日語詞,可以用一個或多個近義的漢字來寫,例如日語詞 kawa,可以寫成〈河〉或〈川〉;又例如日語詞 oka,可以寫成〈岡〉或〈丘〉。另一方面,兩個或多個有某些共同意義的日語詞可能會用同一個漢字來表示其意思,例如這三個日語詞 getsu、gatsu 和 tsuki,分別解作‘一個月(的時間)’、‘月份’和‘月亮’,但都是寫成〈月〉字。讀者見到〈月〉字,要靠上下文來決定是指哪個詞。
用漢字表示日語名詞的意思相對地簡單,因為日語名詞跟漢語名詞一樣,並不需要表示性、數、格這些語法意義,所以其讀音不會因性、數、格之不同而有異。例如解作‘山’ 的日語名詞 yama,在語法上無論是屬單數、複數、主格、賓格、還是其它,都是讀 yama。用一個漢字〈山〉把 yama 寫出來,已可以代表這個名詞的各種語法意義。
在二十世紀之前,日本人已經使用了古漢文千多年,除了學習用漢字書寫日語詞彙外,還藉古漢文吸納了大量漢語詞彙。這些漢語詞彙自然是用漢字寫的,並用漢語讀音讀出來。例如解作‘官署’的漢語詞{役所},日本人很早便藉古漢文〈役所〉吸納了這個詞,自然也會用漢語讀音把〈役所〉讀出來,今日這個詞的漢語讀音在日語中演變成 yaku sho,寫成〈役所〉。日文中的漢字,一般除了可以跟字的意思用日語“訓讀”出來,還可以跟字的漢語讀音“音讀”出來。例如〈山〉這個字可以用日語“訓讀”成 yama,也可以跟漢語“音讀”成 san。
古漢文中的一個字,在絶大多數的情況下已經代表一個語素,而且讀音只是一個音節。例如〈山〉這個字,代表漢語語素{山},而讀音只有一個音節。漢語語素絶大都是單音節,一個音節表示一個語素,語素相互之間的組合極之靈活,組合起來可以產生極多詞彙,而且組合出來的詞彙仍然相當簡約,一般都是兩、三個音節的長度,而雙音節或三音節詞彙已能表達相當複雜的意思。日本人就是看中了漢語和漢文這種特性,把很多漢語詞彙及其漢文原封不動地借過來用,亦利用漢語和漢文的特性來構建自己的詞彙。這種利用漢語詞構建日語詞彙的方法既方便又容易,日本人可以利用這種方法不斷創造出新的日語詞彙。
日文經常藉漢文吸納漢語詞,例如 sanrin 這個漢語詞,便是從漢文〈山林〉吸納過來的。這個漢語詞表示‘山上的樹林’,日語想簡潔地表達這個意思,可以用 sanrin 這個漢語詞,並會跟隨漢語讀音把詞讀成 sanrin,亦自然會跟隨漢文把詞寫成〈山林〉。〈山林〉中的〈山〉字只能音讀成 san,但在別的詞語中,〈山〉字可以訓讀成 yama。例如日語詞組 yama no te,一般寫成〈山の手〉,其中的〈山〉和〈手〉字分別要訓讀成 yama 和 te。te 解作‘方向’或‘方位’,yama no te 整個詞組解作‘山那邊’。日語詞 te 的基本義是‘手’,而‘方向’或‘方位’則是其引伸義,所以 te 寫成〈手〉。〈山の手〉受到漢語構詞方法的影響,亦可以寫成〈山手〉。由於這個是日語詞,所以〈山の手〉只會訓讀成 yama no te,並沒有音讀。由此可見,同一個〈山〉字,在〈山林〉這個詞中要音讀成 san,而在〈山の手〉這個詞組中則要訓讀成 yama。
日本最著名的山是富士山,日本人今天普遍叫它做 fujisan,在古代卻未必是同一個叫法。這座山曾以〈富士山〉、〈福慈岳〉、〈不二山〉、〈不盡山〉等名字出現在日本的古代文獻中。這座山在遠古未有文字之前已經存在,相信當時的人會給它一個有意義的名字。在漢字東傳至日本時,這座山的名字相信已經歷過數以千年計的演變,由於在日常生活中經常使用,名字的讀音可能經歷過一些省略和變化,剩下了類似 fuji 這個讀音,山名最初的讀音和意思因年代久遠,已無從稽考,今天的日本人即使作出種種推敲,仍莫衷一是。在日語中,{山}叫做 yama 或 take,在漢字東傳至日本後,日本人會嘗試用漢字把 fuji yama 或 fuji take 這名字的音或義寫出來。如果名字本身的意義不清楚而又要寫義的話,就只能武斷地賦予名字一個全新的意義。有人把山名寫成〈不二山〉,意思是‘獨一無二的山’;亦有人寫成〈不盡山〉,意思是‘延綿不絶的山嶺’。山名這樣寫是否恰當,則見仁見智。如果寫音,日本人會選擇一些合適的漢字,一方面其讀音要能跟 fuji 吻合,另一方面其意義又要能跟這座宏偉莊嚴的山岳匹配。有人把山名寫成〈富士山〉和〈福慈岳〉,名字的音和義似乎都頗恰當。最終日本人接受了〈富士山〉這個名字,並約定俗成地叫山做 fujisan。
日文吸納了的漢語詞,如果在日語中長時間廣泛地使用,就自然會演變成日語常用詞彙的一部分。例如東京地鐵最繁忙的一條路線叫做 yamanote sen,寫成〈山手線〉。sen 是日語中的漢語詞,解作‘路線’,寫成〈線〉。sen 這個漢語詞已經成為日語中的一個重要詞彙,而〈線〉這個字亦已經變成日文中的一個常用字。在〈山手線〉這個路線名字中,〈山手〉會訓讀成 yamanote,而〈線〉則會音讀成 sen。在日文中,一個漢字可以只有音讀,如〈線〉;也可以只有訓讀,如〈鴨〉,〈鴨〉只會按解作‘鴨’的日語詞讀成 kamo。但很多漢字既可以音讀,亦可以訓讀,例如〈山〉字,有時會音讀成 san,有時會訓讀成 yama。至於何時音讀何時訓讀,則要看情況和使用習慣而定。日本人有了日語口語和書面語的知識,常用詞中漢字的讀法一般是不成問題的。
日文通過漢文吸納了大量漢語詞彙,包括單、雙、三音節詞以至四音節的中國成語,並利用單音節漢字創造出大量的雙音節詞彙。因此,日文可以只用兩個漢字就能表達各種不同的意思。但由於日語音節結構比漢語更為簡單,而音節數目又比漢語少很多,所以日文借用漢字時,很多原本不同音的漢字在日語中卻變成同音,造成很多漢字詞彙同音,即使是雙音節詞彙,同音的詞彙可以多達二、三十個。例如:讀 seika 的雙音節詞,《現代日漢大詞典》就收錄了21個,在日文中寫成:〈成果、正貨、正課、正価、生花、生家、声価、青化、青果、斉家、清歌、盛夏、勢家、聖化、聖火、聖歌、精華、製菓、製靴、請暇、臍下〉。[4] 這 21 個漢字詞彙的意思,當然可以用日語講出來,亦可以把漢字作音符用,來書寫講出來的日語。例如〈盛夏〉這個漢字詞彙的意思,日語可以說成 natsu no sakari,這三個日語詞分別解作‘夏天’、‘的’、‘全盛時期’,如果把漢字作音符用,這三個日語詞可以寫成〈奈川乃左加利〉。日文吸納了漢文〈盛夏〉一詞,就可以只用兩個義符表達出‘盛夏’ 的意思,並跟漢語讀成 seika。讀者見到〈盛夏〉這個漢字詞彙,會很快就明白作者的意思。這些漢字詞彙,是在不同情況下逐一借過來的,借來時並不會全面考慮到該詞彙跟別的詞彙同音的問題。這 21 個雙音節詞都同音,在日常說話中會不會引起一些混淆呢?如果會的話,又怎樣解決呢?
我們首先要明白,這 21 個雙音節詞都屬書面語,有部分在口語中很少會用到。此外,說話時的實際情況,差不多已能弄清楚 seika 究竟是指哪一個詞。即使出現一些混淆的情況,人們亦有方法解決。
解決方法之一是把詞的意思用日常日語講出來,例如〈生花〉這個詞,日語可説成 ikebana,意思是‘插花’;又例如〈臍下〉這個詞,用日語可説成 shitahara,意思是‘小肚子’。另外一個解決方法是利用一個日文漢字可以有多種讀法的特性,把雙音節詞的部分或全部讀音變成另一種讀法,例如把〈勢家〉這個詞讀成 seike,而這個讀音只解作‘有勢力的家族’。又例如〈青化〉這個詞,有人會讀成 aoka,〈青〉字之所以讀 ao,是因為日本人見到〈青〉這個常用字時,習慣用解作綠色之日語詞 ao 讀出來。又例如〈聖化〉這個詞,可讀成 shouke,讀法中的兩個音節都跟 seika不同。
用漢字寫日語詞音的利弊
寫日語的第二種方法是把漢字作音符用,將和歌歌詞的音節逐一寫出來。這種方法是易寫不易讀,尤其是在日文草創期間。詞與詞之間的界限會較難清楚地分辨開來,讀者需要靠母語的幫助,把歌詞讀出來,才較容易把歌詞中的用辭弄清楚。此外,讀者見到漢字音符,會嘗試用漢音讀出來,但漢音可能跟日語讀音有些偏差,所以亦要靠母語補足來弄清楚是哪個日語詞,然後按日語把各個漢字音符讀出來。還有一點,用這種方法寫出來的歌詞會相當冗長。
萬葉假名一覽表
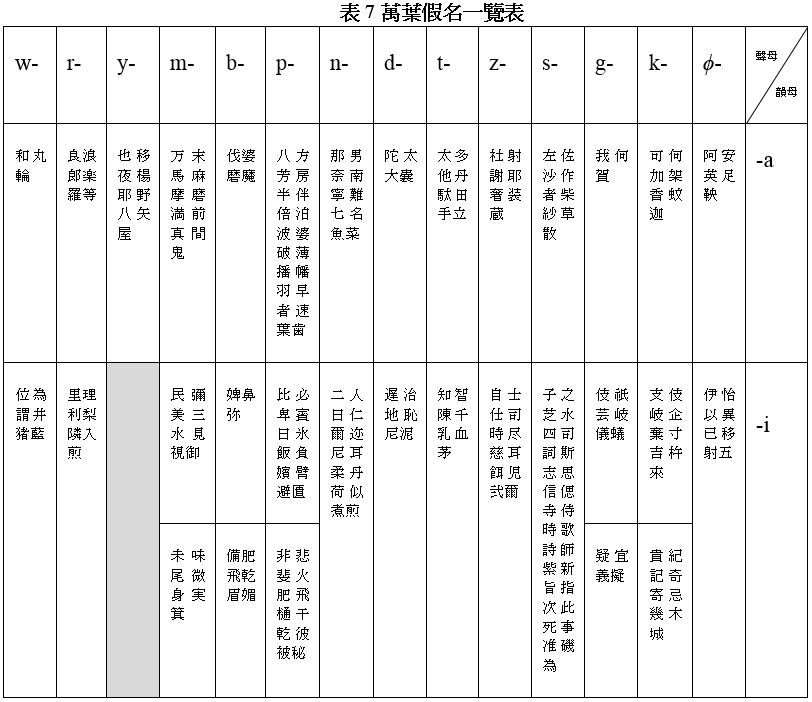
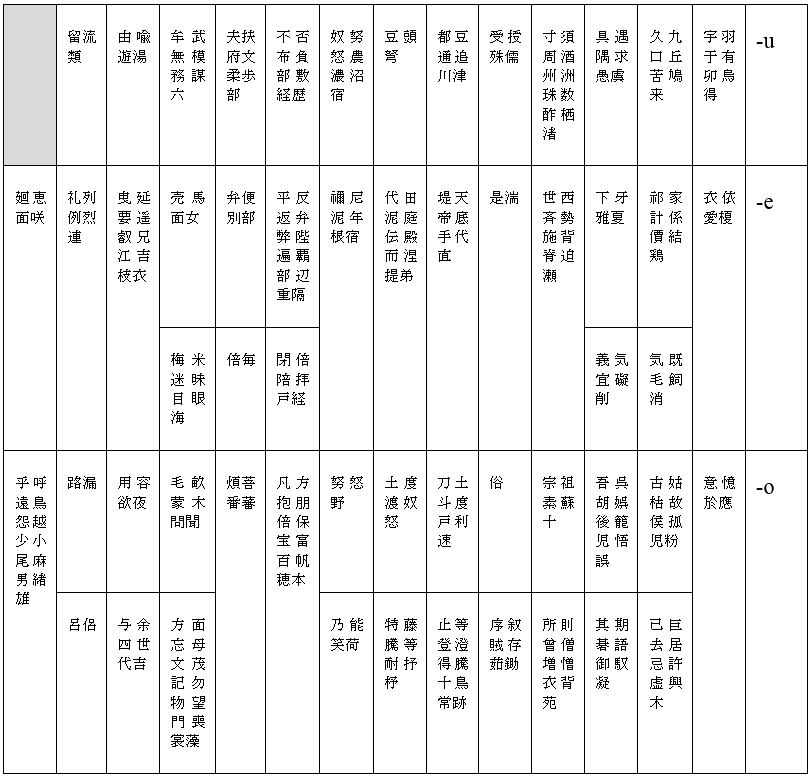
上文說過,《萬葉集》編纂的年代由七世紀後半葉至八世紀後半葉,歷時約一百年。編纂者用漢字作音符來書寫日語的音節,並不是全新的嘗試。其實從五、六世紀稻荷山古墳的古鐵劍開始,至七、八世紀的《日本書紀》、《古事記》和《萬葉集》,日本人已經積累了至少二百多年用漢字作音符來書寫日語的經驗。從《萬葉集》可以看到日本人怎樣利用漢字書寫日語音節。這些作音符用的漢字,現在稱為「萬葉假名」。以下是萬葉假名一覽表。
古代日語音節的結構很簡單,除了幾個 V 音節外,其餘都是 CV 的音節。C 表示音節開頭的輔音 (consonant),中國音韻學稱為聲母;V 表示音節結尾的元音 (vowel),中國音韻學稱為韻母。下面的一覽表顯示了日語所有的 V 音節和 CV 音節,這個表要從右至左讀過去,最右邊的直行顯示韻母,由上至下依次是:-a, -i, -u, -e, -o;最上面的橫列顯示聲母,由右至左依次是:ϕ-, k-, g-, s-, z-, t-, d-, n-, p-, b-, m-, y-, r-, w-(ϕ-表示零聲母)。有學者認為,古代日語有八個元音,即a, i1, i2, u, e1, e2, o1, o2,比現代日語多三個,所以古代日語的音節比現代日語多。但亦有學者認為,古代日語只有五個元音,古代日語的音節之所以亦比現代日語多,是因為古代日語有複輔音,如 kw- 和 gw-。從一覽表可以看到,在《萬葉集》年代的日語中,由 V 或 CV 構成的音節一共有 88 個;由於同一個日語音節可以用不同的漢字寫出來,所以表中的萬葉假名一共有 612 個,而不只是 88 個。
萬葉假名是怎樣產生的
現在用幾個實例,來說明萬葉和歌的作者是怎樣利用漢字來寫出日語的音節,例如 /a/。有作者覺得漢字〈阿〉的讀音最接近日語的 /a/,所以用〈阿〉代表 /a/音。這是用漢字寫日語音節最基本和自然的方法。用這種方法表示日語音節的其他例子有:〈以〉/i/、〈呂〉/ro/、〈波〉/pa/。但當作者一時間未能找到合適的同音漢字時,他就只好用別的方法解決。有作者覺得讀 /an/ 音的漢字〈安〉,其前截的讀音最接近日語的 /a/,所以用〈安〉代表 /a/ 音。亦有作者用〈英〉字代表 /a/ 音,原因有可能是在日本古代〈英〉的讀音,跟〈安〉一樣,都是 /an/,所以用〈英〉代表前截的讀音 /a/。在上面的萬葉假名一覽表中,一個日語音節都是用一個漢字來代表。但有些漢字,有的作者會用來代表兩個日語音節,例如〈信〉、〈覽〉和〈相〉。這三個漢字的漢語讀音,其實都是以鼻音結尾的單音節字,但日本人聽起來卻覺得最似日語的 /shi na/、/ra mu/、/sa ga/,所以用〈信〉、〈覽〉和〈相〉分別來代表這些音,一個漢字代表兩個日語音節。
上一段所述的方法,都是利用漢字本身的讀音來注出日語的音節。然而,亦有作者想到把漢字訓讀以注出日語音節。例如〈足〉字,按其意思可用日語訓讀成 /a shi/,有作者覺得開頭的音節就是日語的 /a/,所以用〈足〉代表 /a/ 音。有作者竟然想到用〈嗚呼〉兩個漢字來代表日語 /a/ 音,因為在古漢文中〈嗚呼〉是感嘆詞,按其意思可用日語可以訓讀成 /a/,所以用〈嗚呼〉代表 /a/ 音。
日本人用訓讀漢字的方法,可以很準確地表示日語的音節,上述的〈足〉和〈嗚呼〉是兩個例子。和歌的作者有時會訓讀一個漢字,代表一個日語音節,例如訓讀〈毛〉來表示 /ke/ 音;有時會訓讀一個漢字,代表兩個日語音節,例如訓讀〈鴨〉來表示 /ka mo/ 這兩個音節;有時會訓讀兩、三個漢字,代表一個或多個日語音節,例如訓讀〈五十〉來表示 /i/ 這個音節。
在萬葉和歌的年代,日語的 /a/ 音,可以用〈阿、安、英、足、嗚呼〉來代表。哪一種方法最好,需要經過長時間使用和自由比拼才能決定。從表 7 可以看到,一個日語音節可以用不同的漢字音符來表示,例如 /si/ 這個音節有多達 29 個漢字音符可供選擇。音符的數量經時間洗禮後會慢慢減少,那些不被大多數人接受的音符會被淘汰,只有那些被最多人接受的音符會保留下來。但即使如此,在二十世紀之前,一個日語音節仍然可以有多種寫法,可見要達成一音一符的共識,並不是一件容易的事。
混合使用義符和音符的利弊
寫日語的第三種方法,是用漢字寫實詞的義,但同時亦以漢字為音符去寫虚詞或助詞的音。這種方法的缺點是很難從外形上分辨出哪個漢字是寫義,哪個漢字是寫音。例如在同一首和歌中,〈之〉字有時是音符,寫出日語的 /si/ 音,有時卻是義符,寫出日語虛詞 {no} ‘之’ 的意思。讀者可能要把和歌閱讀多遍,藉上下文之助,才能知道哪個漢字是音符,哪個是義符。作者有時甚至不把虚詞寫出來,要讀者跟據上下文補上沒有寫出來的虚詞。這種種不足之處,都會增加閱讀的困難。
八世紀初安萬侶寫《古事記》時,會用小字注明哪些漢字是作音符用。這種方法雖然有助讀者辨認漢字音符,但很不方便,因為先要離開原文來閱讀注解,再折回原文來辨認音符,這明顯不是一種有效率的閱讀方法。
萬葉假名的演化
日本奈良時代的末期,即八世紀末(中國唐代),用來書寫日語音節的漢字音符,數量開始逐漸減少,並只集中於某一些漢字。此外,人們覺得楷書漢字的筆劃繁複,為求書寫便捷,開始用草書寫漢字。草體漢字雖然較難辨認,但由於漢字音符逐漸只集中於百多個形體較為簡單的常用字,所以只要這些漢字能夠約定俗成地寫成某些固定的形體,即使字形寫得很草率,人們也能把這些字認出來。例如 {no} 這個使用頻密的虚詞,在八世紀時可以用以下七個漢字音符寫出來:〈努、怒、野、乃、能、笑、荷〉,但後來卻逐漸集中於〈乃〉或〈能〉,而且字體寫得越來越草,到了十二世紀初,{no} 這個虚詞一般寫成乃字或能字的草體,見下圖:

安萬侶寫《古事記》時,會嘗試用古漢文寫出稗田阿禮所口述的日本歷史,但當意譯遇到困難時,就索性把漢字作音符用來音譯日語,由於用漢字音譯日語會比意譯容易,所以這也不失為一個折衷的辦法。日本人用漢字記錄《萬葉集》的和歌時,如上文所述,基本上有三種方法:1. 全用漢字義符;2. 全用漢字音符;3. 混合使用漢字義符和音符。方法 1 的困難是,記錄者有時很難找到恰當的漢字去表達某些和語詞的意思,而讀者也往往不容易根據漢字義符來重構原來的和語歌詞。方法 2 則比較容易,記錄者不難用漢字作音符把歌詞的音節逐個寫出來,而讀者亦頗容易根據漢字音符來重構和語歌詞。方法 3 是混合使用方法 1 和 2,《萬葉集》年代的漢字音符數量頗多,同一個和語詞可以用不同的漢字音符寫出來,記錄者要寫出一些常用的實詞時,會自然聯想到某個經常與之匹配的漢字義符,而不會費神去找適當的漢字音符,但方法 3 亦有以下一個缺點:義符和音符在外形上沒有分別,讀者閱讀歌詞時要靠上文下理把兩者分辨開來。
平假名是怎樣產生的
《萬葉集》之後的第二本和歌總集,是編撰於公元十世紀初(中國唐末)的《古今和歌集》。這本歌集,一共收錄了千多首創作於八世紀後葉至十世紀初的和歌。之後,和歌集的編寫亦沒有間斷,和歌不斷有人抄寫廣傳。從抄寫於十二世紀初的《古今和歌集》的元永本假名序(下稱《假名序》),可以看到序文是用草體漢字來書寫的。上文說過,日本人為了書寫便捷,早於八世紀開始便用草體來書寫漢字。到《假名序》時,日本人用草體書寫漢字,已累積了三百多年的經驗。
《假名序》主要是使用音符來書寫日語,但中間夾雜着一些義符。音符的字體寫得很潦草,但義符的字體卻像行書多於草書,這現象怎樣解釋呢?用草體寫音符而用行書寫義符這現象,相信是自然演化出來的。在音符中間的漢字義符,起初相信同樣會用草體寫出來,但這些義符如果寫得太潦草,便會較難辨認,因為義符數以千計,寫得越潦草,就會越難猜到是哪一個義符,尤其是那些不常用的義符。音符則不同,同樣用草體寫,音符會比義符容易辨認。音符的數量比義符少得多,而且逐漸減少至百多個。這百多個音符用得非常頻密,所以音符無論寫得多潦草,只要看慣了其字形,也不難辨認。《假名序》中用行書寫的義符,其數量雖然不多,但已能顯示出以下一個道理:義符若能在書體上跟音符有別,便會利於閱讀。人們漸漸明白,義符若寫得較為工整,不但較容易辨認,而且在形體上跟音符有較大的差異,哪個是義符,哪個是音符,就一目了然,大大方便了閱讀。一個義符往往顯示一個實詞,而且很多時是一個名詞,而一個或一組音符則往往顯示一個虚詞,這有助讀者較易掌握句子的結構,以及看出詞與詞之間的分界,閱讀時會較為省力。
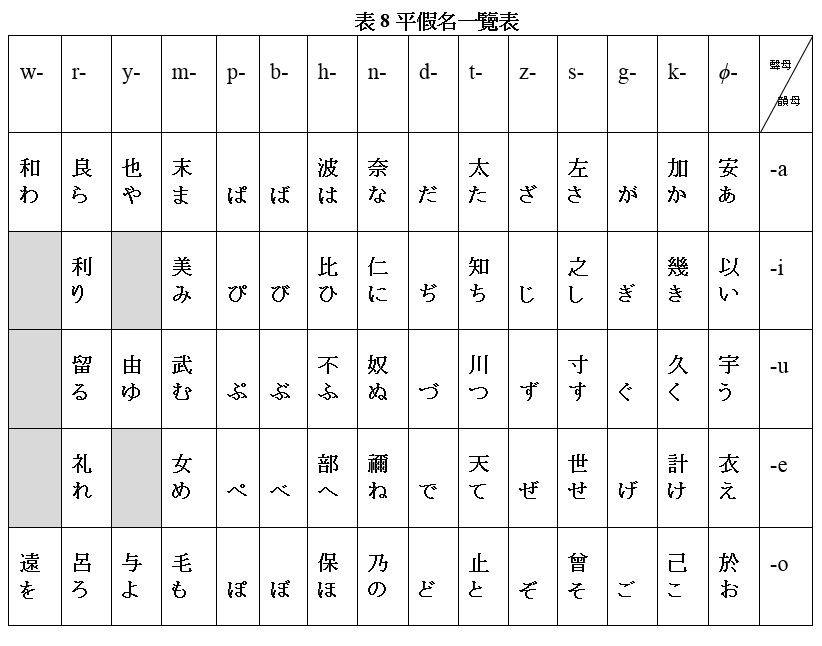
草體的漢字音符,慢慢演變成「平假名」。「平」指「平常」或「普通」,而「假名」指「假借字」。平假名(日文寫作「平仮名」),便是指那些草體漢字音符。二十世紀之前,一個日語音節的平假名寫法一般有幾種。1900年,日本文部省整理出一套標準的平假名,並在學校中大力推行。所以在現代日文中,一個日語音節的平假名寫法,基本上只有一種,例如 no 這個日語音節,用平假名只能寫成〈の〉。
下面是標準平假名的一覽表,假名排列的方法,跟表 7 中的萬葉假名一樣。表中第一個平假名是〈あ〉,源自上面〈安〉字的草書體。〈あ〉左邊的平假名是〈か〉,源自上面〈加〉字的草體。〈か〉左邊的的平假名是〈が〉,由〈か〉和濁點〈 ゛〉組成,〈か〉讀 /ka/,〈が〉讀 /ga/,〈が〉中的濁點〈 ゛〉表示 /k/ 的濁音 /g/。聲母為 /p/ 的平假名則用半濁點〈 ゜〉表示,例如〈ば〉讀 /ba/,〈ぱ〉讀 /pa/,〈ぱ〉中的半濁點〈 ゜〉表示 /b/ 的清音 /p/。明白了濁點和半濁點的作用之後,其餘平假名的讀音及其字源,都大致可以從下面的平假名一覽表中看出來。
從下表亦可以看到,現代日語一共有 5 個 V 音節和 65 個 CV 音節 (比《萬葉集》編纂年代的 88 個音節少了 18 個),其中 45 個音節各由一個基本符號來表示,如〈か〉和〈は〉,其餘 25 個音節則各由一個基本符號附加一個記號(如濁點和半濁點)來表示,如〈が〉和〈ぱ〉。
片假名是怎樣產生的
日本在平安年代初,即公元九世紀初,出現了後來稱為「片假名」的楷體漢字音符。這些漢字音符寫在漢文經典著作中行與行之間的空白地方,用來注出漢字的日語讀法。例如《禮記》中的一句“物有本末,事有終始”,其中的〈物〉字解作‘事物’,日本人會按其意思用日語訓讀成 mono,如果要用萬葉假名注出 mo 和 no 這兩個音,則分別有 20 和 7 個漢字音符可供選擇(見表 7)。由於行與行之間的空間有所限制,人們會盡量選取形體較為簡單的音符,例如會選用〈毛〉和〈乃〉這兩個音符來寫 mono 這個日語詞。為了更方便地在狹窄的空間書寫,人們會進一步把音符簡化,只寫出音符的一部分,例如把〈毛〉和〈乃〉分別寫成〈モ〉和〈ノ〉。由於日語音節的數量不多,而所用的漢字音符的數量亦逐漸減少,以致用來用去都是同一組有限的漢字音符,所以即使把這些音符省略成簡單的記號也行。這些記號式的音符,只取原來音符的一部分,所以稱為片假名。可是,注同一個音,不同的人可能會選用不同的音符,而即使是簡化同一個音符,所選取的部分亦可能會不同。片假名的寫法,起初是各師各法,百花齊放,同一個音會有很多種不同的寫法。到了十二世紀(中國宋代),片假名的寫法才開始慢慢達成共識。1900 年,除平假名外,日本文部省亦整理出下面的一套標準片假名,一個日語音節的片假名寫法,亦基本上只有一種,例如 no 這個日語音節,用片假名只能寫成〈ノ〉。
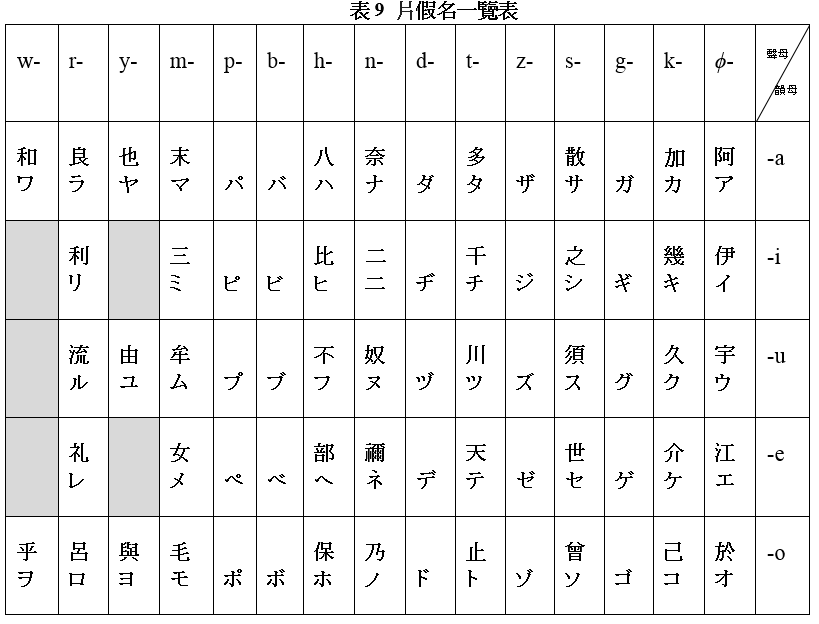
上面是日文所有片假名的一覽表,假名排列的方法,亦跟表 7 中的萬葉假名一樣。表中第一個片假名是〈ア〉,源自上面〈阿〉字楷體的左面偏旁。〈ア〉左邊的片假名是〈カ〉,源自上面〈加〉字楷體的左面偏旁。〈カ〉左邊的的片假名是〈ガ〉,由〈カ〉和濁點〈 ゛〉組成,〈カ〉讀 /ka/,〈ガ〉讀 /ga/,〈ガ〉中的濁點〈 ゛〉表示 /k/ 的濁音 /g/。聲母為 /p/ 的片假名則用半濁點〈 ゜〉表示,例如〈バ〉讀 /ba/,〈パ〉讀 /pa/,〈パ〉中的半濁點〈 ゜〉表示 /b/ 的清音 /p/。明白了濁點和半濁點的作用之後,其餘片假名的讀音及其字源,都大致可以從表中看出來。
現代日文所使用的平假名和片假名,除了表 8 和表 9 所列出的代表一個 V 音節或 CV 音節的假名外,還有一個分別寫成〈ん〉和〈ン〉的平假名和片假名,用來寫出 V 音節或 CV 音節後面的鼻音。這個鼻音一般讀成 [n],但在 /m/ 、/b/ 、/p/ 音之前讀 [m],而在 /k/ 、/g/ 音之前則讀 [ŋ] 。〈ん〉這個符號,一般認為是〈无〉字的草體,而〈无〉是〈無〉的簡體字;〈無〉是萬葉假名之一,代表 /mu/。解作‘閱覽’的漢語借詞 {覽},在古代日語中讀成 /ramu/,亦當然可以寫成〈覽〉。如果用萬葉假名寫音,可以寫成〈良無〉。/ramu/ 的尾音弱化後,便演變成 /ram/,但日語並沒有用閉口音結尾的習慣,所以 /ram/ 會進一步演變成 /ran/。當〈良無〉讀成 /ran/ ,〈無〉就代表了 /n/ 音。如上文所述,〈ん〉這個平假名一般看作是〈无〉字的草體,而〈无〉是〈無〉的簡體。至於片假名〈ン〉,它是表示 /n/ 音眾多記號其中一個。大概由於其他記號的形狀近似別的假名,慢慢遭到淘汰,日文片假名後來只採用〈ン〉來表示 /n/ 音。
現代日語的漢語詞,不少是以 /n/ 音結尾的,例如 /kantan/,可以用漢字寫成〈簡単〉,亦可以用平假名寫成〈かんたん〉,當中的〈ん〉就代表 /n/ 音。在英語借詞中,〈mansion〉可以用片假名寫成〈マンション〉,當中的〈ン〉就代表 /n/ 音。在日語口語中,亦有一些音可以用 /n/ 音來替代,例如日語どのような… /donoyo:na…/,解作‘怎樣的……’,很多時會簡單說成どんな… /donna…/。換句話說,/do/ 後面的 /n/ 音,取代了のよう /noyo:/ 這兩個音節,而這個 /n/ 音在這裏寫成〈ん〉。
假名與日語音節的關係
在現代日文中,假名與日語音節的關係很簡單,一個假名基本上代表一個日語音節,而一個日語音節則基本上用一個假名代表,但有三個假名屬例外:〈を、へ、は〉。日語的 /o/,一般寫成〈お〉,但有時會寫作〈を〉;假名〈へ〉一般讀 /he/,但有時會讀成 /e/;假名〈は〉一般讀 /ha/,但有時會讀成 /wa/。先談〈を〉。
〈を〉原本讀 /wo/,當開頭的 /w/ 音消失後,/wo/ 演變成 /o/,與固有的 /o/ 合併,所以〈を〉現在讀 /o/,只是在假名的名稱上,人們今天仍稱〈を〉為 /wo/,以別於原先就稱為 /o/ 的〈お〉。〈を〉今天讀 /o/,理論上可以用〈お〉來代替,因為代表 /o/ 的假名是〈お〉,但現代日文保留了〈を〉的最重要用法:〈を〉用來代表日語中一個經常使用的助詞。這個助詞以前讀 /wo/,今天讀 /o/,用來表示前面的詞就是句子中的賓詞。例如這句:〈花を見る〉,讀 /hana o miru/,解作‘賞花’。句子中的 /o/,就是那個能顯示賓詞的助詞,寫成〈を〉。〈を〉顯示句子中的賓詞是〈花〉,讀者一見到〈を〉,馬上就能掌握整個句子的結構,知道是‘賞花’的意思。如果句子寫成〈花お見る〉,句子的結構就沒有〈花を見る〉那樣清楚, 而且句子越長,句子的結構就越不明顯,因為〈を〉可以説是專門用來顯示賓詞,但〈お〉則有多種功能。假如用〈お〉代替〈を〉,/o/ 音便只有一個寫法,非常簡單,但閱讀效果就稍為遜色,因為〈お〉除了要擔當起顯示賓詞的功能之外,還有其他功能,例如,它是很多實詞讀音的一部分,而且會經常用來美化一些詞彙,例如把〈茶〉美化成〈お茶〉。如果〈お〉在長句中出現,那就要看清楚它究竟是哪一種功能。〈を〉這個符號,除了專門用來顯示賓詞之外,字形還相當獨特和易於辨認,所以,即使顯示賓詞的助詞今天讀 /o/,仍然應該保留〈を〉的寫法,而不應該用〈お〉代替。〈を〉其實已經變成了一個能顯示賓詞的語素符號,而並不僅是一個音節符號這樣簡單。〈を〉最接近漢字一字一語素的功能,可以說是一個可遇不可求的假名。
在現代日文中,〈へ〉一般讀 /he/,但用來代表方向助詞時,則讀 /e/。現代日語的 /he/ 音,在古代日語中原本說成 /pe/。到了平安年代初(公元九世紀初),當 /p/ 這個雙唇塞音弱化成雙唇塞擦音 /ɸ/(吹腊燭所發出的聲音,近似 /f/ 音),/pe/ 音便說成 /ɸe/。葡萄牙傳教士在十六世紀末編撰《日葡字典》時,便因為日語的 /ɸe/ 聽起來像葡語的 /fe/ 音而用羅馬字〈fe〉來拼寫 /ɸe/。在日語詞中間或詞尾的 /ɸe/ 音,有時會受到前面元音的影響而說成 /βe/,葡萄牙人聽起來像葡語的 /ve/ 音,所以會用〈ve〉來拼寫 /βe/。(夾在兩個元音中間的 /ɸ/,有時會濁音化而變成近似 /v/ 或 /w/ 音的 /β/。但是,在詞頭的 /ɸe/ 音,卻因為前面沒有元音而保持不變。)/βe/ 聽起來近似日語固有的 /we/,所以後來與 /we/ 合併。/w/ 是個介乎元音與輔音之間的通音,弱讀時會容易消失,因此很多不同的語言包括日語都有 /w/ 音消失的現象。日語的 /we/ 在 /w/ 消失後,便演變成 /e/,與日語固有的 /e/ 合併。總結上文所述,日語的 /pe/ 音,先演變成 /ɸe/,再分兩路演化,一由 /ɸe/ 直接演變成今天的 /he/,一由 /ɸe/ 先演變成 /βe/,再演變成 /we/,/w/ 音消失後,便演變成今天的 /e/。演變的過程如下:
|
/pe/ → /ɸe/ |
/he/ | |
| ↗ | ||
| ↘ | ||
| /βe/ → /we/ → /e/ |
現在用兩個例子來說明 /pe/ 怎樣演變成 /he/ 和 /e/。第一個例子是解作‘減少’的和語詞,這個詞相信以前是說成 /perasu/,後來說成 /ɸerasu/,今天則說成 /herasu/;第二個例子是解作‘上’的和語詞,這個詞相信以前是說成 /upe/,後來先後說成 /uɸe/、/uβe/、/uwe/,再說成今天的 /ue/。上述兩個和語詞中原本的 /pe/ 音,分別演變成今天的 /he/ 和 /e/,在現代日文中分別寫成〈へ〉和〈え〉。
解作‘減少’的和語詞 /perasu/ 先演變成 /ɸerasu/,寫法是〈減らす〉或〈へらす〉;再演變成 /herasu/,寫法卻維持不變,仍然是〈減らす〉或〈へらす〉。換句話說,〈へ〉以前代表 /ɸe/,今天則代表 /he/。解作‘上’的和語詞 /upe/ 先演變成 /uɸe/,再演變成 /uβe/,寫成〈上〉或〈うへ〉;/uβe/ 再演變成 /uwe/,當 /w/ 音消失後,就變成今天的 /ue/,寫成〈上〉或〈うえ〉。換句話說,漢字的寫法〈上〉保持不變,但假名的寫法則跟隨讀音的演變由〈うへ〉改為〈うえ〉。〈へ〉(或其前身)先後代表 /βe/、/we/、/e/,而〈え〉則代表 /e/。〈うへ〉先後表示 /uβe/、/uwe/、/ue/ 的讀音,而〈うえ〉則表示 /ue/ 的讀音。
表示方向的日語助詞 /e/,相信是源於漢語借詞{邊}。起初,這個詞大概讀 /pje/,後來演變成 /ɸe/,寫成〈へ〉。由於這個詞是後置助詞,出現於詞組的尾部,所以 /ɸ/ 會夾在兩個元音中間。當這個 /ɸ/ 音濁音化後,/ɸe/ 會演變成 /βe/,而 /βe/會再跟固有的 /we/ 合併,當 /w/ 音消失後,會演變成 /e/,與日語固有的 /e/ 合併。很多字的 /e/ 音,以前都寫成〈へ〉,但現在都跟隨讀音的演變改寫成〈え〉。可是,方向助詞的讀音雖然變了 /e/,其寫法〈へ〉卻保持不變,屬例外。
為甚麼方向助詞的寫法〈へ〉維持不變?一個合理的推測是代表方向助詞的〈へ〉,既簡單易寫,又容易辨認;而且,方向助詞的前面很多時是用漢字寫出來的地方名。當筆劃較為複雜的漢字置於字形簡單的假名〈へ〉之前面時,漢字和假名的強烈對比會令到兩者都顯得清楚易讀。例如以下一句〈東京へ行く〉,表示‘去東京’。如果方向助詞按今日讀音寫成〈え〉,就變成〈東京え行く〉,閱讀效果會稍為遜色。日本人經過長期反覆試驗,會覺得方向助詞還是寫成〈へ〉較為優勝。
在現代日文中,〈は〉一般讀 /ha/,但用來代表主題助詞時,則讀 /wa/。現代日語的 /ha/ 音,在古代日語中原本說成 /pa/。/pa/ 音的演變過程,很類似上文所述的 /pe/ 音,/pa/ 先演變成 /ɸa/,再分兩路演化,一由 /ɸa/ 直接演變成今天的 /ha/,一由 /ɸa/ 先演變成 /βa/,再演變成今天的 /wa/,與日語固有的 /wa/ 合併。演變的過程如下:
|
/pa/ → /ɸa/ |
/ha/ | |
| ↗ | ||
| ↘ | ||
| /βa/ → /wa/ |
日文中詞頭的〈は〉(或其前身)先後代表 /pa/、/ɸa/ 和 /ha/,而詞中或詞尾的〈は〉(或其前身)則可能先後代表 /pa/、/ɸa/、/βa/ 和 /wa/。
反映現代日語的五十音圖顯示,/wa/ 行基本上只保留了 /wa/ 這個音節。現代日語有部分詞彙中的 /wa/ 音,是由 /pa/ 音演變出來的,所以舊時是用假名〈は〉來表示。今天,源自 /pa/ 的 /wa/ 音,除了主題助詞保留舊時的寫法〈は〉之外,則一律按音寫成現代的〈わ〉,因為固有的 /wa/ 音是用〈わ〉來代表。現在用兩個例子來說明 /pa/ 怎樣演變成 /ha/ 和 /wa/。
第一個例子是解作‘花’的和語詞,這個詞相信以前是說成 /pana/,後來說成 /ɸana/,今天則說成 /hana/;第二個例子是解作‘川’的和語詞,這個詞相信以前是說成 /kapa/,後來說成 /kaɸa/、/kaβa/,今天則說成 /kawa/。上述兩個和語詞中原本的 /pa/ 音,分別演變成今天的 /ha/ 和 /wa/,在現代日文中分別寫成〈は〉和〈わ〉。
/hana/ 和 /kawa/ 這二個和語詞,以前是怎樣寫的?。/hana/ 以前的讀音是 /ɸana/,寫成〈花〉或〈はな〉,當讀音演變成 /hana/ 後,寫法卻保持不變,仍然是〈花〉或〈はな〉。換句話説,〈は〉以前代表 /ɸa/,今天則代表 /ha/。/kawa/ 以前的讀音是 /kaβa/,更古老的讀音是/kaɸa/,但無論是 /kaɸa/ 還是 /kaβa/,都寫成〈川〉或〈かは〉。當讀音演變成 /kawa/ 後,除了〈川〉或〈かは〉的寫法外,又多了〈かわ〉的寫法,因為 /wa/ 的固有寫法是〈わ〉。當〈かは〉這個傳統寫法被淘汰後,/kawa/ 今天只會寫成〈川〉或〈かわ〉。
日語中的主題助詞原本讀 /pa/,後來演變成 /ɸa/,寫成〈は〉。由於這個詞是後置助詞,出現於詞組的尾部,所以 /ɸa/ 會濁音化而先後演變成 /βa/ 和 /wa/,再與固有的 /wa/ 合併,但〈は〉的寫法卻維持不變。主題助詞今天讀 /wa/,理論上可以用〈わ〉來代替,因為代表 /wa/ 的假名是〈わ〉,但現代日文仍然用〈は〉來代表日語中的主題助詞。為甚麼不用〈わ〉來代替〈は〉?
原因可能是〈わ〉這個假名的負擔頗重。〈わ〉除了用來寫出很多詞彙中的 /wa/ 音之外,凡是以 /-u/ 結尾的動詞的否定形、使役形和被動形,都會用上 /wa/ 音,並寫成〈わ〉,所以〈わ〉是一個出現得頗為頻密的假名。可能為了減輕〈わ〉的負擔,〈は〉就保留下來代表日語中的主題助詞。
/wa/ 作為主題助詞,在日語中用得非常頻密,用來提示前面的詞就是說話的主題,講完 /wa/ 之後,會稍作停頓以突顯主題,因而在日常溝通中起了一個很重要的作用。主題助詞 /wa/ 是日語中一個非常重要的詞,如果有一個形體獨特的假名來代表就很理想,因為一見到這個假名,就能馬上掌握到整句句子的主題。主題助詞今天寫成〈は〉,閱讀效果不差,但〈は〉除了用來表示主題助詞外,還用來表示很多實詞中的 /ha/ 音,沒能像賓詞助詞〈を〉一字一詞所收到的清楚閱讀效果。〈は〉外形近似〈ほ〉(〈は〉讀 /ha/ 或 /wa/,而〈ほ〉讀 /ho/),沒有〈を〉那樣獨特。其實主題助詞可以說比賓詞助詞更為重要,很值得創造一個形體獨特的假名與它配合,但最大的困難是創造出一個大家都會接受的假名。創造這個假名的一個途徑,是從表示 /pa/ 音的萬葉假名中選出一個可以造出形象獨特的假名。
〈を、へ、は〉這三個不按今日讀音書寫的助詞假名,其實只是保持傳統的寫法,並不是刻意地與別不同。這三個例外的假名,只不過在日文的發展過程中,與其他的寫法比較,仍然有其優勝之處,所以能保留下來。文字在實際使用中汰弱留強,正正是文字自然發展之道。現代日文容許有〈を、へ、は〉這三個例外,是有其道理的。
怎樣用假名寫日語的長音節
表 8 的平假名和表 9 的片假名一覽表顯示,現代日語一共有五個 V 音節和六十五 CV 音節。這些都是短音節,分別用七十個不同的平假名或片假名來代表。一個假名代表一個短音節,而一個短音節所佔的時間叫做一個音拍 (mora)。日語除了這七十個一個音拍長的短音節外,還有一些兩個音拍長的長音節。例如日語除了 /ka、i、ju、se、mo…/ 這些一個音拍長的短音節外,還有 /ka:、i:、ju:、se:、mo:…/ 這些兩個音拍長的長音節。/ka、i、ju、se、mo…/ 這些短音節用平假名和片假名可以分別寫成〈か、い、ゆ、せ、も…〉和〈カ、イ、ユ、セ、モ…〉,而 /ka:、i:、ju:、se:、mo:…/ 這些長音節,用平假名和片假名則可以分別寫成〈かあ、いい、ゆう、せい、もう…〉和〈カー、イー、ユー、セー、モー…〉。
〈か、い、ゆ、せ、も〉這五個假名分別讀 /ka、i、ju、se、mo/,這五個短音節分別以 /-a、-i、-u、-e、-o/ 這五個元音結尾。/ka、i、ju、se、mo/ 這五個短音變成長音時,分別寫成〈かあ、いい、ゆう、せい、もう〉。〈かあ〉由〈か〉和〈あ〉組成,〈か〉讀 /ka/,〈あ〉讀 /a/,合在一起時就很自然地表示了 /ka/ 的長音 /ka:/。同理,〈いい〉由兩個〈い〉組成,都讀 /i/,而〈ゆう〉由〈ゆ〉和〈う〉組成,〈ゆ〉讀 /ju/,〈う〉讀 /u/,所以〈いい〉和〈ゆう〉亦很自然地表示了 /i/ 和 /ju/ 的長音 /i:/ 和 /ju:/。可是,/se/ 和 /mo/ 的長音卻分別寫成〈せい〉和〈もう〉。從假名個別的讀音來看,〈せい〉讀 /se/ 和 /i/,而〈もう〉讀 /mo/ 和 /u/,但在現代日文中,〈せい〉卻主要用來表示 /se/ 的長音 /se:/,而〈もう〉則表示 /mo/ 的長音 /mo:/。
上文說過,/ka:、i:、ju:、se:、mo:/ 這五個長音節用片假名可以寫成〈カー、イー、ユー、セー、モー〉。由此可見,片假名寫長音的方法比平假名簡單,長音一律用〈ー〉這個符號表示,〈ー〉表示前面的片假名要讀長音。
怎樣用假名寫日語的拗音
現代日語的基本音節是 V 音節和 CV 音節,但很多漢語借詞的讀音都含有 C+/j/ +V 這種在日文中稱為“拗音”的音節。例如,讀作 /kjoka/ 的漢語借詞,可以用漢字寫成〈許可〉,亦可以用平假名寫成〈きょか〉。〈きょ〉表示 /kjo/ 這個一音拍長的單音節拗音。/kjo/ 中的 /j/,漢語音韻學稱為介音,/j/ 是個介乎元音和輔音兩者之間的音,/j/ 延長就會變成元音 /i/,而 /i/ 縮短就會變成輔音 /j/。〈きょ〉用來寫出 /kjo/ 這個拗音,〈きょ〉中的〈ょ〉寫得比正常大小較細。〈き〉表示 /ki/,而〈よ〉表示 /jo/。〈きよ〉表示 /ki jo/ 兩個音節,而〈きょ〉則表示 /ki jo/ 這兩個音節要壓縮為 /kjo/ 一個音節。又例如用日語可親切地稱呼家人為 /tjan/,寫成〈ちゃん〉,〈ちゃ〉表示 /ti ja/ 這兩個音節要壓縮為 /tja/ 一個音節。日語中的拗音很多都屬長音,例如解作‘今天’的 /kjo:/,平假名寫成〈きょう〉,最尾的〈う〉表示〈きょ〉/kjo/ 要讀長音。/kjo:/ 用片假名則寫成〈キョウ〉,最尾的〈ウ〉表示〈キョ〉/kjo/ 要讀長音。又例如解作‘龍’的 /rju:/,平假名寫成〈りゅう〉,最尾的〈う〉表示〈りゅ〉/rju/ 要讀長音。
怎樣用假名寫日語的促音
現代日語亦有一些稱為“促音”的音節。在日語中, (C1)V + C2V 有時可以用促音說成 (C1)VC2 + 促音 + C2V。(C1)V + C2V 佔兩個音拍,說促音時則變成三個音拍的長度,因為促音本身佔一個音拍。例如解作‘前面’的和語詞 /sa ki/,寫成〈さき〉,用促音可說成 /sak ki/,寫成〈さっき〉,意思引申為‘剛才’。〈さっき〉中的〈っ〉寫得較小, 表示〈さき〉要讀促音。〈っ〉這個促音符號本身不發聲,它只是用來表示〈さき〉 /sa ki/ 要讀促音。由於 /ki/ 開頭的輔音是塞音,所以這裏的促音是一個停頓。/sa ki/ 讀促音時變成:/sak + 停頓 + ki/。/sak/、/停頓/ 和 /ki/ 各佔一個音拍。/sa/ 之所以說成 /sak/,是因為 /k/ 要預先準備好發後面的 /ki/ 音。/sak/ 中的 /k/,是蓄勢待發的 /k/ 音,要在停頓之後才跟接着的音節 /ki/ 融合,一起說出來。/sak/ 這音節是 (C1)VC2 一個例子,而 (C1)VC2 這類音節給日語簡單的 (C1)V 音節增添一點變化。
日語說促音時,有時會把部分音節省去。(C1)V C2V + C3V 有時可以用促音說成 (C1)VC3 + 促音 + C3V,原本的 C2V 省去了,(C1)V C2V 變成 (C1)VC3。例如解作‘一次’的日語詞 /ik kai/,寫成〈一回〉或〈いっかい〉。/ik kai/ 是從 /itʃi/ + /kai/ 變化出來的。/itʃi/ 解作‘一’,寫作〈一〉或〈いち〉;/kai/ 解作‘回’,寫作〈回〉或〈かい〉。/itʃi/ 這裏用促音說成 /ik/,/tʃi/ 音省去了,在停頓之後接上後面的音節 /kai/,所以 /itʃi/ + /kai/ 用促音會說成:/ik + 停頓 + kai/。
如果上一段的 C3 是摩擦音,例如 /s/,那麼,用促音說 (C1)V C2V + C3V 時, 就會變成 (C1)VC3 + /s/ + C3V,由摩擦音 /s/ 取代停頓,/s/ 音因而延長,變成佔一個音拍的 /s:/。例如解作‘一切’的漢語借詞 /is sai/,是從 /itʃi/ + /sai/ 變化出來的。/itʃi/ + /sai/ 用促音說成:/is + s + sai/,寫成〈一切〉或〈いっさい〉。
小結:書寫日語詞彙的方法
日語詞彙可以分為三大類:(一)稱為和語詞的固有日語詞,(二)源自漢語的日語詞,(三)借自外語的日語詞。書寫這些詞彙的字體有三種:(一)漢字,(二)平假名,(三)片假名。現代日文的基本文體是混合使用假名和漢字來書寫日語口語。現在用兩句日文來說明日文是怎樣運作的。
3 日文是怎樣運作的?
日文的運作方法
現以下面一句摘錄自網上日文字典中的例句,來解釋日文是怎樣運作的。

上面的例句,較為接近日常口語,所用的詞彙以和語詞為主。例句一共有 24 個字符,其中 5 個是漢字,3 個是片假名,其餘 16 個都是平假名。單就這三種字符在日文中出現的頻率來說,這句例句似乎頗有代表性,因為在現代日文中,平假名一般使用得最普遍,漢字次之,接着是片假名。
現在先介紹上面例句中大家最熟悉的漢字。這些漢字都是以楷書的形式出現,在形體上跟草書的平假名有很大的分別。上文說過,日文中的義符若能在形體上與音符有別,便會較容易閱讀。所以在現代日文中,義符的印刷體選擇用楷書漢字,以別於草書的平假名。〈指輪〉這兩個日本漢字,把日語中的和語詞 yubiwa ‘戒指’ 的意思寫出來,所以〈指輪〉會訓讀成 yubiwa。yubiwa 由兩個詞 yubi 和 wa 組成:yubi 解作‘手指’,寫成〈指〉;而 wa 解作‘環’或‘輪’,寫成〈輪〉。在日文中,有很多名詞都是用兩個漢字寫出來的,但讀音不一定是訓讀。換句話説,這些名詞不一定是和語詞。例如〈幸福〉這兩個漢字,用來寫出 kouhuku 這個漢語詞,表示‘幸福’的意思,會跟漢音讀成こうふく kouhuku 。〈身に〉中的〈身〉,表示和語詞 mi ‘身體’的意思,所以〈身〉這裏會訓讀成 mi。〈私〉用來寫出和語詞 watashi ‘我’的意思,所以〈私〉這裏會訓讀成 watashi。〈幸せ〉則是一個漢字加一個平假名所寫成的形容詞,解作‘幸福’。〈幸〉在日文中可以代表和語詞 shiawase 或 saiwai,這兩個詞都有‘幸福’ 的意思。shiawase 寫成〈幸せ〉,〈せ〉讀 se,用來提示這個詞要訓讀成しあわせ shiawase;saiwai 則寫成〈幸い〉,〈い〉讀i,用來提示這個詞要訓讀成さいわい saiwai。〈幸い〉一般解作‘幸運’或‘幸好’,亦可以解作‘幸福’。〈幸せ〉和〈幸い〉中的〈せ〉和〈い〉,俱用來提示〈幸〉的讀音。
例句開頭的三個片假名〈ダイヤ〉,把解作‘鑽石’這個英語借詞 diamond 開頭的讀音 daia 寫出來。diamond 整個詞可以用片假名寫成〈ダイヤモンド〉,讀 daiamondo,但一般簡寫成〈ダイヤ〉已足夠了。日文中的片假名,主要用來寫出外語詞的讀音。
日文中的平假名,用來寫出和語詞和漢語詞的讀音。現逐一介紹例句中的 16 個平假名。第一個是在〈ダイヤの指輪〉這個詞組中出現的〈の〉,寫出和語詞 no 的讀音,no 表示戒指的原料屬鑽石。跟着的三個平假名是〈なんて〉,用來寫出和語詞 nante 的讀音,{なんて} 表示‘甚麼的’或‘……之類’,含有‘沒有甚麼了不起’的意思。〈身に〉解作‘身上’,這裏的平假名〈に〉寫出和語詞 ni 的讀音,ni 有‘那裏’的意思。〈つけて〉這三個平假名,把 tsukete 這個日語動詞的讀音寫出來。這裏的〈つけて〉亦可以寫成〈着けて〉、〈付けて〉或〈附けて〉。書寫日語動詞,可以用漢字寫出詞的基本意思,例如用〈着〉、〈付〉或〈附〉寫出 tsukete 這個詞的基本意思,再用〈け〉這個假名提示前面的漢字應訓讀成 tsuke;〈て〉這個假名,把動詞後綴 te 的讀音寫出來。te 是語法詞中的詞綴,屬接動詞形,緊接詞幹的後面,表示動作的延續。〈つけて〉這三個假名,除了代表解作‘穿戴’ 的詞外,還可代表其他的詞,但在上面的例句中,〈つけて〉前面的〈身に〉已提示了其‘穿戴’的意思,所以即使不寫成〈着けて〉、〈付けて〉或〈附けて〉,而寫成〈つけて〉,意思亦頗為清楚。日語的動詞一般置於賓詞的後面,跟漢語或英語不同,例句中的〈つけて〉就置於賓詞〈指輪〉的後面。〈いない〉用來寫出和語詞 inai 的讀音。和語詞 inai 是由 iru 和 nai 兩個詞併成。iru 表示目前的狀態,而 nai 則表示‘沒有’;〈つけていない〉表示‘沒有穿戴着’。〈けど〉讀 kedo,把解作‘雖然’的和語詞 keredomo 的簡略讀法 kedo 寫出來。‘雖然’這個意思,可以用不同的和語詞表達出來,例如 shikashi、noni、mottomo、tatoe、daga。這些語法詞,一般會用平假名把其讀音寫出來,但有時也會用漢字加假名寫出來, 例如 shikashi 一般會寫成〈しかし〉,但有時會寫成〈然し〉;〈然〉表示和語詞 shikashi ‘雖然’的意思,〈然〉後面的假名〈し〉則提示〈然〉應訓讀成 shikashi。中文的〈雖然〉會置於句首,但日文的〈けど〉卻置於句末。〈私は〉中的平假名〈は〉,把日語語法詞 wa 的讀音寫出來,表示句子所敍述的主題是〈私〉。〈幸せ〉中的平假名〈せ〉,其作用已在上文解釋了,不贅。〈だ〉把常用動詞 da 的讀音寫出來,〈だ〉這裏解作‘是’。在日文的句子中,動詞一般會置於句末,例如這裏的動詞〈だ〉。
日文用上漢字、平假名和片假名三種字體不同的字符,其實是很有道理的。以上面的例句為例,當在一連串的平假名中,夾雜用上漢字和片假名時,閱讀例句就會變得較為容易。如果例句全部用平假名寫出來,就會變成:
だいやのゆびわなんてみにつけていないけど、わたしはしあわせだ。
面對這樣的一句日文,讀者首先要做的工作是斷句,即是要費神把句子分成一段一段意思完整的單位,而例句中的漢字和片假名則基本上把斷句大部分的工作做妥了,所以讀者會看得較為舒服自在。
此外,漢字、平假名和片假名這三種字體不同的字符,在日文中都各有其功能。和語詞中的實義詞,既可以用漢字把其意思寫出來,例如例句中的〈指輪〉、〈身〉和〈私〉,亦可以用平假名把其讀音寫出來,例如例句中的〈つけて〉。理論上,例句中的〈指輪〉、〈身〉和〈私〉,亦可用平假名把詞彙的讀音寫出來,但用平假名寫出來的詞彙,卻沒能像漢字那樣直接表示詞彙的意思。至於例句中為甚麼使用〈つけて〉而不用〈付けて〉或〈着けて〉,上文已經解釋了,不贅。和語詞中的語法詞,一般都是用平假名寫出來,例如例句中的〈の〉、〈なんて〉、〈に〉、〈けど〉、〈は〉。
日語中的漢語詞,當然是指源自漢語的詞,這些詞的音和義自然取自漢語,亦可以用與其對應的漢字寫出來。用漢字寫出來的漢語借詞,自然會音讀。漢語借詞一般屬實義詞,以名詞為主。下面的一句日文,有三個都是用漢字寫出來的漢語詞:〈漢字〉、〈研究〉、〈従事〉。這三個漢語詞的意思跟中文相同,分別讀成 kanji、kenkyuu、jyuuji。讀音模仿漢語,但不一定很相似。這三個漢語借詞原屬名詞,可是,〈研究〉和〈従事〉後面如果加日語詞〈する〉suru,就會變成動詞。〈している〉shite iru 是〈する〉suru 的現在進行式。〈従事している〉表示‘現正從事’。

值得注意的是:用漢字寫出來的詞,可以是和語詞,不一定是漢語詞,例如解作‘我’的和語詞 watashi,既可以用平假名寫成〈わたし〉,亦可以用漢字寫成〈私〉;而漢語詞可以用假名寫出來,不一定要用漢字,例如在日語中讀成 sanpo 的漢語詞 {散步},既可以用漢字寫成〈散歩〉,亦可以用平假名寫成〈さんぽ〉sanpo。在日文中,和語詞及漢語詞的寫法很有彈性,可以用漢字,也可以用平假名,甚至混合使用漢字和平假名。外語借詞,例如借自英語的詞,一般則是用片假名寫出來。擬聲詞、擬態詞、以及在文中需要強調的詞,都可以用片假名來寫。
4 日文是否為一種好的文字?
上文說過,在二十世紀之前,日本的公私文字是以漢文為主,但在二十世紀之後,情況則有很大的改變,公私文字基本上全用日文,把接近口頭語的日語用漢字和假名寫出來,如上一節所引用的例句 1 和 2。
如果從八世紀寫成的《古事記》算起,到了二十世紀初,日本人反覆試驗使用漢字書寫日語已有千多年之久。漢字專為書寫漢語而設,而漢語和日語卻是兩種很不同的語言,所以用漢字書寫日語一點也不容易,實在需要長時間的反覆試驗,才能找到一些可行的方法。在反覆試驗期間,會發覺全用義符並不方便,因為日語的語法詞彙如助詞和動詞的詞形變化,用音符表示會較為方便;而全用音符亦會產生很多問題,例如句子比較冗長,詞與詞之間的界限要分辨開來等;義符音符兼用,似乎比較可行,但兩者的形體同樣是漢字,很難分辨哪個是義符,哪個是音符,閱讀起來亦會有困難。當只作音符用的平假名和片假名產生了,而且在形體上跟作義符用的漢字有了明顯的分別,閱讀就變得比以前方便很多。到了二十世紀初,日本人總的認為,漢字和假名混合使用,是書寫日語最好的方法。這種書寫日語的方法,是日本人從使用漢字書寫日語千百年的經驗中自然而然地總結出來的,一直沿用至今天,基本不變。
一些外國學者覺得,混合使用漢字和假名這種書寫日語的方法太複雜,既然假名基本上可以把日語音節準確地寫出來,為甚麼日本人不完全捨棄難學的漢字而光用假名呢?筆者把這個問題請教一些日本人,他們的回答可歸納為以下兩點:(1) 假名只是用來表音,而假名本身沒有意思;(2) 混合使用漢字和假名寫出來的日文,閱讀起來會較為舒服。從這兩點可以窺見混合使用漢字和假名的妙處。
日本人説假名本身沒有意思,言下之意是每個漢字都是有意思的。日本人把漢字看成義符,而把假名看作音符,這兩種符號清楚分開,閱讀日文時會更為方便。上文說過,在日文發展史上,曾經有一段頗長的時間全用漢字來寫日語,漢字既可作義符用,又可作音符用,但義符和音符在形體上卻沒有分別,閱讀起來很不方便。後來從漢字演化出形體很不同的假名,專用來表音,漢字則專用來表義,形體有別的義符和音符分工,漢字和假名各司其職,閱讀時會更加方便。在現代日文中,漢字一般表示日語詞的意義,屬義符,而假名則表示日語詞的讀音,屬音符。
閱讀漢字混合假名寫出來的日文,日本人覺得舒服,主要原因是漢字往往代表實詞,而且往往表示一個詞的開始,漢字混合假名,一方面可以省去一部分分詞的功夫,另一方面因為漢字與假名的分工,可以粗略地顯示句子的語法結構, 令讀者閱讀時不用那麼費勁。而且,使用漢字時,句子的意思會較為明確,省卻分辨同音詞的麻煩,閱讀起來更為省事、舒服。
西方語言學者見到日文混合漢字與假名,而且有兩套假名,大都覺得日文十分複雜。有人甚至認為,在實用方面,沒有比日文更糟糕的文字。日本人用一套假名,基本上已足夠把整套日語清楚準確地寫出來,但日本人明擺着沒有這樣做,當中一定有一些很好的理由。由此可見,文字發展之道,並不光是追求簡單,這裏所謂「簡單」,有兩種意思。一是捨棄義符,光用音符;一是捨棄形體複雜的符號,光用形體簡單的符號。先說第一種意思。
在公元前約二千年,蘇美爾文曾經嘗試逐漸捨棄義符,光用音符,但發覺效果不及傳統的義符和音符兼用的方法,所以選擇走回頭路。蘇美爾文之所以走回頭路,是因為蘇美爾人嘗試過使用義符的好處。同理,阿卡德文在普遍使用音符的同時,仍保留若干數量的義符。日文中義符和音符兼用的好處,對日本人來說是顯而易見的。
現在談第二種意思。文字作為視覺符號,要有某程度的複雜性,才能產生足夠的對比,使到各種不同的符號,都能清楚顯現出來。符號全部複雜,固然難寫,亦不容易辨認;符號全部簡單,當然易寫,但其實並不是如想像般易認,速讀時仍要花點精神來辨認符號。符號有部分複雜、有部分簡單,外形的分別會較大,當這些文字排在一起時,繁簡相間,錯落有致,才能產生強烈的對比,閱讀起來就會較為容易。
從一些檢字表中排列漢字的方法,可以見到上面所說的道理。在這些檢字表的頁首或頁旁,供讀者檢索的漢字會按部首和筆劃數目排列,同一部首、筆劃數目相同的漢字會排在一起。所以,想要檢索的漢字,無論是複雜還是簡單,都會跟其前後的字的形體相近。現以《現代日漢大詞典》檢字表 2205 頁和 1991 頁的頁首所排列的漢字為例,來顯示這個情況。2205 頁所排列的「門」字部漢字較為複雜,而 1991 頁的「亻」字部漢字則較為簡單。為了節省空間,詞典中的字一般會較為細小,現把頁首排列的漢字縮小至接近實際的大小,如下面所示 (如上文提過,因技術原因,這裡不能把字縮小至接近實際的大小):
開閑間閘閨聞閣閥関閲閻閼闍鬩閾闊
休伐件任伊仲仰伉倅伝仮住位
要快速檢索上面字體較小的漢字會較為吃力,想找到要檢索的漢字,可能要放慢閱讀速度以及較用神。
在一段中文或日文中,一般的情況是有些字筆劃數目多,有些字筆劃數目少,彼此在形體上有較大的差別,這就會產生明顯的對比,使文字更易閱讀。在現代日文中,大部分的情況是漢字和平假名混合使用,漢字是筆劃較多、字體端正的楷書,而平假名則是筆劃較少、字體飄逸的草書,兩者在形體上的差別很大,有明顯的對比,再加上漢字和平假名在語法上的粗略分工,使到現代日文閱讀起來既容易又舒服。再以日文例句 1 和 2 為例,即使字體縮小到跟上面供檢索的兩行漢字一樣大小,日文熟練的讀者很快便把下面兩句句子中的各個詞彙認出來,原因有很多種,主因之一是漢字和平假名在形體上的強烈對比。
ダイヤの指輪なんて身につけていないけど、私は幸せだ。
私は漢字の研究に従事している。
中文的印刷體基本上全用楷書,沒有像平假名這種草體符號,因而沒有像日文中楷體與草體的對比,句子中的字是否好認,完全有頼每一個字本身在形體上的特性,所以漢字的形體是否獨特,在閱讀上十分重要。漢字形體的演變,即使只從甲骨文算起,經過金文、大篆、小篆到隸書,已歷時千多年。漢字發展至隸書,形體已慢慢穩定下來。一筆一劃都寫得清楚的楷書,萌芽於漢魏之際,到了南北朝成為主要的字體,跟今天所用的繁體字基本上相同。經過千多年的錘鍊,楷書中每個字的字形大致上都相當獨特,雖然難免有一些近形字,但問題不大,可以利用上文下理把字很快認出來,基本上影響不到楷書的高效率閱讀功能。
如果純粹從學習和書寫的角度來看,日文光用平假名就最簡單和方便。可是,日本人覺得,保留漢字雖然會增加學習者和書寫者的負擔,但卻會大大增加日文的可讀性,所以始終選擇混合使用漢字和假名。由此可見,在書面語的運用上,閱讀一環是至為重要的。當西方學者發覺,同一個漢字在日文中可以代表多個不同日語詞,而同一個日語詞卻又可以有多個不同漢字的寫法,便覺得日文出奇地複雜。他們不免會問,如果日文捨棄複雜的漢字而只用簡單的假名,日文豈不是會變得易學很多?現在用〈上〉這個可以代表多個日語詞的常用日文漢字做例子,來解釋日文為甚麼會保留漢字的寫法。下表列出日文〈上〉字的用法(這部分的資料,主要來自《現代日漢大詞典》):
表 10 〈上〉字在日文中的用法
| 日文 | 讀音 | 備註 |
| 上 | jou | jou這個讀音源自漢語詞,如果用假名可寫成じょう,但這個音在日語中可以表示 27 個不同的日語詞,如果用假名來寫,就唯有倚靠上文下理來決定是哪一個詞,但這樣做就要多費一些工夫。jou 這讀音,在日文中可以有多至 27 個不同漢字的寫法,例如〈上〉、〈状〉、〈城〉、〈情〉、〈場〉、〈条〉等,如果用這些漢字寫出來,意思當然會比用假名明確得多,毋須那麼費神來決定其意思。即使由 jou 組成的雙音節詞彙,仍可代表幾個不同的詞語,表示多種不同的意思,例如 joushou,可以代表多至 7 個不同的詞語,表示 7 種不同的意思,如果用假名寫成〈じょうしょう〉,其意思要由上下文來決定,但如果用漢字寫成〈上昇〉、〈常勝〉、〈丞相〉等,意思就明確得多。 |
| 上 | ue | ue 是日語常用詞,一般解作‘上面’,可用漢字寫成〈上〉或用假名寫成〈うえ〉。例如‘桌子上的書’,日語可說成 tsukue no ue no hon,常寫成〈机の上の本〉,亦常寫成〈机のうえの本〉,句中的 ue 可寫成〈上〉或〈うえ〉。 |
| 上 | uwa | uwa 是日語常用詞,一般解作‘上邊’或 ‘表面’,可用漢字寫成〈上〉或用假名寫成〈うわ〉。例如‘表皮’,日語可說成 uwakawa,可用漢字寫成〈上皮〉,亦可用假名寫成〈うわかわ〉,還可用假名和漢字寫成〈うわ皮〉,例子中的 uwa 可寫成〈上〉或〈うわ〉。又例如‘外衣’,日語可說成 uwagi,可以用假名寫成〈うわぎ〉,但卻經常會用漢字〈上着〉寫出來。在日文中,經常出現〈下着〉、〈水着〉、〈夏着〉、〈冬着〉的寫法 (分別解作‘內衣’、‘泳衣’、‘夏衣’、 ‘冬衣’)。可能受到這些寫法的影響,uwagi 經常會寫成〈上着〉。 |
| 上 | kami | kami 的讀音可以代表幾個同音的和語詞,分別解作‘高高在上’、‘紙’和‘咀嚼’。解作‘高高在上’ 的和語詞,按意思可用漢字寫成〈上〉,例如表示‘瞧不起人’,日語可以說成 kami kara mesen,可以寫成〈上から目線〉,句子的字面意思是‘由上(往下)看的目光’,句子中的〈上〉寫出 kami 這個詞;‘高高在上’ 的引伸義則有多種,按意思用漢字分別可寫成:〈神〉、〈髪〉、〈長官〉、〈守〉。解作‘紙’和‘咀嚼’ 的和語詞,按意思用漢字分別可寫成:〈紙〉、〈噛み/嚙み/咬み〉(み這個假名讀 mi,顯示前面的漢字要訓讀成 kami)。此外,kami 的讀音還可代表多個同音的漢語借詞,用漢字分別可寫成:〈加味〉、〈佳美〉、〈香美〉等。由此可見,kami 如果按讀音用假名寫成〈かみ〉,其意思可以有許多種;用漢字寫,意思則相當明確。即使如此,如果上文下理夠清楚,日文仍然可以用假名〈かみ〉來寫 kami 的讀音,而不用漢字。 |
| 上げ | age | age 這個和語詞,解作‘舉起’,用漢字可寫成〈上げ〉(げ這個假名讀 ge,顯示前面的漢字要訓讀成 age);其引伸義則是‘油炸’,有可能指油炸時所產生氣泡把食物升起,一般用漢字寫成〈揚げ〉。油炸食物,日語說成 agemono,約定俗成地寫成〈揚げ物〉。油炸的方法,日語說成 agekata,一般寫成〈揚げ方〉。油炸用的油,日語說成 ageabura,一般寫成〈揚げ油〉。 |
| 上る | noboru | noboru 這個和語詞,解作‘往上’,引伸義則有多種,用漢字可分別寫成〈上る〉、〈登る〉或〈昇る〉(る這個假名讀ru,很多時表示動詞的詞尾;這裏的動詞〈上る〉、〈登る〉或〈昇る〉要讀成 noboru);noboru 這個詞亦可全用假名寫成〈のぼる〉。要表示‘登山’,日語可說成 yama ni noboru,一般寫成〈山に登る〉,亦可全用假名寫成〈やまにのぼる〉,noboru 是動詞。要表示‘上樓梯’或‘登上王位’,動詞 noboru 亦都會寫成〈登る〉。要表示‘太陽上昇’、‘煙上升’或‘温度上升’,動詞 noboru 則一般會寫成〈昇る〉。要表示‘上斜坡’、‘上京’、‘提出話題’或‘提上日程’,動詞 noboru 卻一般會寫成〈上る〉。 |
從上表可以看到,日語中讀 jou 的漢語借詞,有 27 個之多。這些詞如果都用假名寫,則每個詞都會寫成〈じょう〉,〈じょう〉究竟是哪一個詞,要靠上文下理來決定;但如果用漢字寫,就會寫成27個不同的漢字,從這些漢字,馬上就可以知道是哪一個詞。由此可見,日文有時需要使用漢字來提高閱讀的效率。日語中的同音詞着實不少,在單音節漢語借詞中,同音的很多時都有十多個;即使在雙音節漢語借詞中,同音的常常也有五、六個。這些同音詞如果用漢字寫,會更便於閱讀。
從上表亦可以看到,不同的日語詞可以寫成同一個漢字,例如 jou、ue、uwa、kami、age 這些日語詞,可以寫成〈上〉,因為這些詞都有‘上’的意思。至於〈上〉究竟代表哪一個詞,那就要靠上文下理來決定。如果〈上〉所代表的詞是常用詞,那麽,從上下文會不難知道是哪一個詞。另一方面,同一個日語詞卻可以寫成幾個不同的漢字,因為一個詞可以有多種不同的意思,如果用漢字寫,便可能要用上幾個不同的漢字,例如動詞 noboru,由於它有不同的引伸義,所以會按各種引伸義把詞寫成〈上る〉、〈登る〉或〈昇る〉。要學習 noboru的各種寫法,當然要多費一些工夫,但如果有時間循序漸進地學習,當中的困難並不如西方人想像般大。
假設英語沒有文字,而又只能借用漢字來書寫英語詞彙,那就無可避免會出現上一段所述的情況:不同的英語詞可以寫成同一個漢字,而同一個英語詞卻可以用多個不同的漢字寫出來。例如英語的 on、above、upon、previous、climb、board、mount、alight、ascend、arise、attend 等詞,都可以寫成〈上〉;另一方面,raise 這個英語詞又可以寫成〈舉、抬、揚、升、起、提、養、育、飼、募〉等不同的漢字。概括地説,任何一種外語如果要用漢字來意譯其詞彙,都會遇到類似的情況。
英國文字學者G. 森姆遜 (Geoffrey Sampson) 指出,日文漢字〈物〉有時音讀成 butsu,如〈動物〉doubutsu(〈動物〉的意思跟中文一樣);有時訓讀成 mono,如〈着物〉kimono(〈着物〉在日文中解作‘衣服’)。至於〈着〉字,除了在這裡要訓讀成 ki(這裡的〈着〉字,跟中文一樣,解作‘穿着’),還可以音讀成 chaku,如〈着手〉的〈着〉(〈着手〉一詞,跟中文一樣,解作‘開始’)。森姆遜覺得,日文漢字的讀音相當複雜。
日本人會覺得上述情況並不像表面看那樣複雜。kimono 是常用和語詞,如果用漢字意譯,寫成〈着物〉是很自然的事:ki 譯成〈着〉,因為兩者都有‘穿衣服’的意思;mono 譯成〈物〉,因為都有‘物品’的意思。〈着手〉和〈動物〉則是常用漢語詞,日本人對其讀音和意思都很熟悉,〈着〉和〈物〉在這裏自然會跟漢音讀成 chaku 和 butsu。〈着手〉和〈動物〉這兩個詞,當然可以跟讀音用假名寫成〈ちゃくしゅ〉chakushu 和〈どうぶつ〉doubutsu,但閱讀的效果會比用漢字遜色。日本人學習漢字時,絶不會跟從詞典學習其所有的讀音,而是循序漸進地在上文下理中學習字的讀音。由於常用漢字的讀音跟日常日語有很密切的關係,日本學童要學會千多個常用漢字的讀音和意思,並不是一件困難的事。日本人重視識字敎學,兒童都有機會入學,所以識字率非常高。學習漢字當然要費工夫,但並不像西方人想像般困難。[5] 學了漢字之後,閱讀日文就變得更為方便。
在日文中,漢字的表意功能强,讀者可在瞬間取得其意思。此外,漢字令到詞的界限和句子的結構都變得較為清楚。還有,漢字構詞方便,用兩個漢字便可以構建出無數的新詞,能簡潔地表達新出現的觀念。用漢字寫出來的漢語借詞,很多都蘊含着數千年中國文化的積累,包括其政治制度、禮樂典章、哲學思想、民間智慧,日本人可以現成地借過來,豐富了日語的詞彙。相信日本人會總的認為,漢字是值得學習的。
現代日文是一套很有彈性的文字,日本人可以選擇多用漢字,亦可選擇少用漢字。一些涉及某類內容的文章,例如有關政治制度、選舉程序、法律訴訟的文字,所用的詞彙包含很多非日常的詞彙,用漢字寫出這些詞彙會比較清楚和直接,同時亦可避免同音詞所帶來的混淆。至於那些有關日常生活的文章,則可以考慮多用假名而少用漢字。
現代日文中的漢字,除了使用量可多可少之外,在功能上還有多樣性。漢字一般作義符使用,有時會音讀,有時會訓讀,但漢字偶爾還可作純音符使用,例如〈世話〉和〈沙汰〉。〈世話〉和〈沙汰〉分別讀 sewa 和 sata,解作‘照顧’和‘音信’,把和語詞 sewa 和 sata 的讀音直接寫出來。理論上,和語詞 sewa 和 sata 可以用平假名寫成〈せわ〉和〈さた〉,但平假名的寫法沒有漢字的寫法那樣獨特。〈世話〉和〈沙汰〉這兩個書面語詞彙,經常會在書信中的開頭使用,相信是萬葉假名遺留下來的音符,人們見慣了,覺得好認,所以就讓這些漢字作音符用的詞彙保留下來,並非刻意令日文漢字的用法變得複雜。
上文說過,日語中的和語詞和漢語詞,可以用漢字或平假名寫出來:頗多借自漢語的名詞是用兩個漢字寫成,如例句 2 中的〈漢字〉和〈研究〉;動詞和形容詞則可以混合使用漢字和平假名來寫,如例句 2 中的動詞〈従事している〉和例句 1 中的形容詞〈幸せ〉,亦可以全用平假名來寫,如例句 1 中的否定動詞〈つけていない〉和形容詞〈幸せ〉的另一種寫法〈しあわせ〉;虚詞則一般用平假名寫,如例句 1 和 2 中的〈の〉、〈に〉、〈は〉。混合使用漢字和平假名來寫日語中的和語詞和漢語詞,令日文更為易讀。如果只用平假名來寫,日文會變得難讀一些。
日語中的外語詞,絶大部分來自英語,包括人名、地名和普通詞彙,理論上可以用漢字寫其義,或用假名寫其音。第二種方法遠比第一種容易,所以日文選擇了第二種方法。日文可以選擇用平假名來寫,但平假名的負擔太重了,所以日文選擇用另一套音節符號片假名來寫這些外語詞,以分擔文字一部分的功能。片假名寫音的原理跟平假名同樣簡單,但用片假名寫出來的外語詞彙,是否容易閱讀呢?
在日文句子或段落中,片假名的使用量一般遠比平假名少。片假名通常夾雜在平假名和漢字之間,在形體上另具一格,而且片假名很少像漢字一樣,可以單個地出現,通常以幾個為一組地出現,所以很容易在句子中跟平假名和漢字分辨開來。一般來說,用片假名寫出來的外語詞彙,只要是常見常用,應該容易認出來。例如〈スーパー〉、〈コンビニ〉、〈タクシー〉,分別源自英語借詞 supermarket、convenience store、taxi,解作‘超級巿場’、‘便利店’、‘的士’。這三個英語借詞日語化後,在日文中分別讀成 suupaa、konbini、takushi,日文用片假名把這些外語詞的日文讀音寫出來。可是,用片假名來寫的外語詞彙如果是陌生的話,例如陌生的外國人名、地名和非日常詞彙,相信日本人也要把片假名讀出來才能知道詞彙的讀音。
日文中有很多外國的流行詞彙,大都用片假名來寫,但其中一些詞彙如果只用片假名寫出來,讀者不一定容易明白其意思,所以會用漢字把其意思譯寫出來。例如日本人借用了一個美國政治術語 “containing China”,如果用片假名便會跟讀音寫成〈コンテイニング‧チャイナ〉,〈‧〉這個符號把術語中的兩個詞分隔開,以便於閱讀,但即使如此,一般日本讀者仍不容易馬上取得字的意思,因為這個術語並非日常的日語詞彙,而且“containing”在這裏的用法並不是這個英文字的基本義,一般日本人並不容易明白其意思。為了讓讀者更容易取得整個術語的意思,日文一般把它寫成如下圖所示:

讀者一見到〈包囲中国〉這四個日本漢字,馬上就能取得術語的意思,而漢字上面的縮小了的片假名,則顯示這個外語詞的讀音是 konteiningu chaina。由此可見,用片假名寫陌生的外語詞彙,讀者很多時只知其音而不知其義,但用漢字來譯寫,就能馬上取得外語詞的意義,即使不知道其讀音。圖2 containing China 日文的寫法,兼顧了術語的音和義。這個術語後來日語化了,就跟日語語序創造出一個意思相若的日文詞彙〈中国包囲網〉,跟日文漢字讀成 chuugoku houimou,意思是‘包圍中國的網’。對日本人來說,〈中国包囲網〉這種寫法的可讀性,顯然遠比〈コンテイニング‧チャイナ〉為高。
現代日文用平假名、漢字和片假名三種不同的字體來寫日語,由於是經過長時間實際應用而總結出來的方法,所以能有機而自然地與日語口語連繫起來,所謂道法自然,因此,這種書寫日語的方法應該是相當理想的。所以,在未找到更好的方法之前,不應輕言取代它。在日文中,三種字符同時運用,起了相得益彰的作用,三種字符的可讀性都提升了。如果光用平假名來寫日語,即使用空間把日語詞分隔開,日文的可讀性仍會較為遜色,字符在形體上的變化會少很多。現把上文例句 1 的兩種寫法列於下面,作一對比,以便讀者能看到混合使用假名和漢字的好處。
ダイヤの指輪なんて身につけていないけど、私は幸せだ。
だいやのゆびわなんてみにつけていないけど、わたしはしあわせだ。
我們只要把上文例句 1 的兩種寫法併在一起,就能見到混合使用假名和漢字的好處。例如在第一種寫法中,讀者見到鄰接漢字的〈の〉、〈に〉、〈は〉,就能看出是語法詞,因而很快掌握詞與詞之間的關係以及整個句子的結構;第二種寫法中的〈の〉、〈に〉、〈は〉,則隱身於鄰近的同樣是草體的平假名之中,讀者要多費一點工夫,才能認出各個詞及其間之關係和句子的結構。
代表漢語語素的漢字有形、音、義,日文把漢字這三種要素都利用了。漢字的字形獨特,易於辨認。漢字的讀音在漢語中是單音節,讀音很短,用日語音讀時,亦只佔一至兩個音拍。日文中有很多兩個漢字構成的詞彙,讀音亦只佔三至四個音拍,跟多音節和語詞的長度相若,容易融入日語的體系。日語中由兩個漢字構成的漢語詞,只需要用三至四個音拍就可以表達很複雜的意思。日語的音節結構簡單,音節的數目不多,利用漢字的讀音寫日語音節,不難創造出一套音節表,再演化出兩套假名,用假名基本上可以把全部日語寫出來。有了假名這類音節符號之後,漢字可看作是義符。閱讀的目的,是取得文字的意思。漢字的字形獨特,字義明確,而又只佔一個方塊的空間,所以讀者能在瞬間取得字的意思。
日文的寫法頗有彈性,可以多用漢字,或多用假名。日本政府為了減輕國民學習漢字的負擔,倡議減少使用漢字,於 1923 年發表了 1,962 字的《常用漢字表》,但民間仍按實際需要而使用表外的漢字。第二次世界大戰後,日本政府為了適應當時社會的一般需要,亦於 1946 年制定了 1,850 字的《當用漢字表》,但民間仍有需要使用表外的漢字。1981 年,日本政府年制定了1,945字的《常用漢字表》,但明白到人們有需要使用表外的漢字,其建議只作為指引,民間(包括出版界在内)可以自由使用表外的漢字。我們相信,無論日本政府有沒有指引,只要人們可以自由使用漢字,常用漢字也不會怎樣增加,而會很自然地集中在二千字之內。根據 1977 年發表的《新漢字表試案》,最常用的 1,800 個漢字,在書刋報章上的覆蓋率已可達 99%。由此可見,日本人只要認識一千多個常用漢字,閱讀一般書報應該困難不大。
日本的出版事業蓬勃,競爭激烈,為了爭取讀者,往往很照顧讀者的需要,以青少年為對象的書刋,一般都在漢字旁用平假名注音,而以成年人為對象的書刋,在非常用漢字旁亦會用平假名注音。按理說,出版界所用的日文,應該會以讀者最大的閱讀效益為依歸,而事實上,巿面上的刋物絶大部分都是混合使用漢字和假名,光用假名的刋物可以說是絶無僅有。由此可見,混合使用漢字和假名應該是書寫日文最佳的方法。有些西方學者認為全用假名寫音,理論上應該最為簡單方便,而我手寫我口,亦應該沒有甚麼不可行的地方,這種看法亦有一些日本人認同。但他們只着眼於學習和書寫假名的情況,卻忽略了閱讀這種文字時所會遇到的問題,而閱讀恰好是使用文字最重要的一環。在這個資訊爆炸的年代,人們花在閱讀的時間,遠遠超過花在書寫的時間。對日本人來說,混合使用漢字和假名的日文,明顯比全用假名寫出來的日文易讀得多。由此可見,表音文字不一定勝過義音文字。可是,西方學者卻一般認為簡單易學的表音文字顯然勝過複雜難學的義音文字。這兩種文字孰優孰劣這問題,其實並不像表面看那樣簡單,實在值得所有提倡文字改革的學者們深思。
[1] 這句用羅馬字轉寫的日語,見 William S.Y. Wang和Chaofen Sun 編纂的The Oxford Handbook of Chinese Linguistics (Oxford University Press出版,2015 年印) 第 218 頁。
[2] 表 3 以及隨後的表 4 至 6 的羅馬字注音,都是根據英國牛津大學東方研究學院 B. Frellesvig, S. W. Horn, K. L. Russell 及 P. Sells 所編寫的 The Oxford Corpus of Old Japanese。這些羅馬字所注的讀音,是學者擬構出來的日語古音,跟今日的讀音不一定相同。
[3] 〈娘〉的古義是‘少女’,今義是‘母親’。杜甫《兵車行》中的〈爺娘妻子走相送〉,古代寫作〈耶孃妻子走相送〉。唐代以前,〈娘〉指‘少女’,而〈孃〉則指‘母親’。
[4] 見中國商務印書館與日本小學館所編的《現代日漢大詞典》(1987年第一版) 第 928 至 929 頁。
[5] 何群雄在其《漢字在日本》(商務印書館,2001 年印)一書中,介紹了以下兩位日本漢字工作者對漢字獨到的看法:日本漢學家巿村瓚次郎(1864~1947)認為,兒童的好奇心強,一天敎一個漢字,三年就能學會一千二百字,如果方法得當,循序漸進,不但不會使兒童覺得苦,反而會引起他們極大的興趣(第 25 頁)。小學敎員石井勲根據他十多年的小學敎學經驗,指出漢字比假名更容易為一年級學生所接受;漢字越早敎,反覆練習的機會越多,越容易學會、記牢(第 111 頁)。
Views: 1987